Among the new framework entrants, the Spring framework stands out as the most comprehensive, popular, and mature alternative. With the recent release of Spring 2, this framework is easier to use than ever before. As this article will show, you can easily inject new database persistence capabilities into existing code using the Spring 2 framework and simple configuration. Of course, the capabilities of the Spring 2 framework go far beyond adding database storage capabilities to existing code. In fact, Spring 2 is often used as a lightweight framework alternative to replace the functionality of an entire J2EE stack. By the end of this article, you will have a good appreciation of how you can productively apply the Spring 2 framework to your own work.
Arrival of the non-intrusive frameworks
Just like the conventional software frameworks that we know and love, Spring 2 defines many interfaces to access its features, has API libraries that you can use, and contains many implementation classes that you can inherit from, to tap into its rich functionality. Over and above these “standard” framework components, however, Spring 2 can also add components into existing code by injecting them without disturbing existing code – in a non-intrusive manner. Consider the following example code:public class OrderTaker {
private OrderSystem mySystem;
public void setOrderingSystem(
OrderSystem osys) {
mySystem = osys;
public void takeOrder(Order order){
mySystem.placeOrder(order);
}
}
The OrderTaker is an object that can take an order. The OrderSystem is an interface defined as:
public interface OrderSystem {
void placeOrder(Order ord);
}
There can be many different implementations of OrderSystem, and an OrderTaker will be able to take an order using any one of the implementations.
With the above definitions, we can readily instantiate an OrderTaker object to take an order with the following pseudo-code:
OrderTaker ot = new OrderTaker();…prepare an order called myOrder…
ot.takeOrder(myOrder);You will note that there is one thing missing in the above code – there is no clue as to how an OrderSystem implementation is given to the OrderTaker. The answer lies in setter injection.
Applying setter injection
This technique is called setter injection because a setXXX()method is the means through which the framework will inject an implementation into existing code. Setter injection is a specialization of Dependency Injection (or DI). See box “Inversion of Control and Dependency Injection” for more information on DI.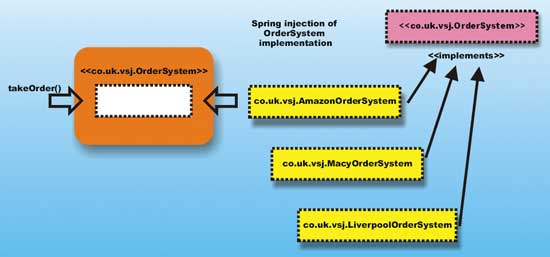
Figure 1: Spring injection
Figure 1 shows how an OrderSystem implementation is injected into the OrderTaker object. There are three available OrderSystem implementations: buy from Amazon, buy from Macys, or buy from Liverpool. The system administrator has the option of injecting or “wiring” any one of the OrderSystem implementations to the OrderTaker.
Note that this injection is totally non-intrusive. The code of OrderTaker does not have to be changed – regardless of which OrderSystem implementation will be used. This non-intrusive injection typically occurs after the OrderSystem code has been compiled – and does not require recompilation of the code. It is performed either by a special compiler, or at load-time using byte-code manipulating enhancers or weavers.
The pseudo-code for this setter injection might be:
- create an instance of AmazonOrderSystem
- create an instance of OrderTaker
- set the orderSystem property of the OrderTaker instance with the instance of AmazonOrderSystem
<bean id=”myOrderTaker” class=”co.uk.vsj.OrderTaker”> <property name=”orderSystem”> <bean class= ”co.uk.vsj.AmazonOrderSystem” /> </property> </bean>An instance of the co.uk.vsj.AmazonOrderSystem class is created by the framework as a bean component. And this bean component is injected into the orderSystem property of an instance of co.uk.vsj.OrderTaker – also created by the framework. Since the framework is responsible for creation and wiring of these component “beans”, it is often called as a container for the components. This is the reason why you will frequently hear that Spring is a lightweight container. The ‘lightweight’ feature is in contrast with the traditional J2EE 1.3 or J2EE 1.4 container, which also contains components (EJBs in this case), but tends to be bulky and heavyweight.
Wiring and rewiring at deployment time
To the industry old timers, byte-code enhancement seems like the old days of binary executable patching. And in some ways, it is. However, the major difference between now and then lies in the formalized methodology, constrained application, and rich tool support for the underlying “automated patching” activity. You are never, and can never work, on the actual binary module-offset level with these frameworks. Instead you provide very high-level instructions on how objects that you create should be “wired” together, and the underlying framework performs the required surgery for you. Figure 2 illustrates the wiring that happens.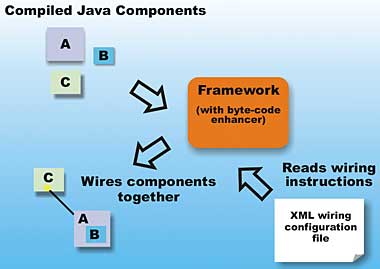
Figure 2: Wiring components together
In Figure 2, the XML configuration file provides the framework with information on how to wire up components A, B, and C. The byte-code enhancement engine of the framework performs the necessary code patching, and the components are wired to specification. Depending on the framework and support, this wiring can occur at:
- compile time with a specialized compiler
- after compilation with a specialized post-processor
- at class loading time with a specialized loading weaver
Creating the base business objects
In this hands-on example, you will start by creating a set of business objects as pure Java classes. Once these objects are created and tested, you will apply the Spring framework to “relational database enable” them.The relationship between the classes is shown in Figure 3.
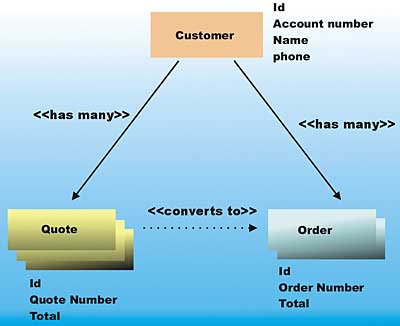
Figure 3: Spring class relationship
A customer can create many quotes, any one of which can be promoted to an order at any time.
Each Customer can have an account number, name, phone, a list of orders, and list of quotes. There is also a unique ID that is used later when you add the database. This listing shows the coding of the Customers class:
import java.io.Serializable;
import java.util.LinkedList;
import java.util.List;
public class Customer implements Serializable {
private int id;
private String accountNumber;
private String name;
private String phone;
private List<Quote> quotes = new LinkedList<Quote>();
private List<Order> orders = new LinkedList<Order>();
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getAccountNumber() { return accountNumber; }
public void setAccountNumber(String accountNumber) {
this.accountNumber = accountNumber;
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public String getPhone() { return phone; }
public void setPhone(String phone) { this.phone = phone; }
public List<Quote> getQuotes() { return quotes; }
public void setQuotes(List<Quote> quotes) { this.quotes = quotes; }
public List<Order> getOrders() { return orders; }
public void setOrders(List<Order> orders) { this.orders = orders; }
public Customer(int id, String accountNumber, String name, String phone) {
this.id = id;
this.accountNumber = accountNumber;
this.name = name;
this.phone = phone;
}
public Customer( String accountNumber, String name, String phone) {
this.accountNumber = accountNumber;
this.name = name;
this.phone = phone;
}
public Customer() {}
public Order convertToOrder(Quote quote) {
Order ord = new Order(quote.getQuoteNumber() + 1000, quote.getTotal());
addOrder(ord);
removeQuote(quote);
return ord;
}
public void addOrder(Order order) { orders.add(order); }
public void addQuote(Quote quote) { quotes.add(quote); }
public void removeQuote(Quote quote) { quotes.remove(quote); }
}
The addOrder(), addQuote(), and removeQuote() method are used to manage the list of orders and quotes. The convertToOrder() method enables you to convert an existing quote to an order.
A Quote class contains a quote number and total. It is shown here:
package co.uk.vsj.spring2.domain;
import java.io.Serializable;
public class Quote implements Serializable {
private int id;
private long quoteNumber;
private Customer customer;
private long total;
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public Customer getCustomer() { return customer; }
public void setCustomer(Customer customer) { this.customer = customer; }
public long getQuoteNumber() { return quoteNumber; }
public void setQuoteNumber(long quoteNumber) {
this.quoteNumber = quoteNumber;
}
public long getTotal() { return total; }
public void setTotal(long total) { this.total = total; }
public Quote(int id, long quoteNumber, Customer customer, long total) {
this.id = id;
this.quoteNumber = quoteNumber;
this.customer = customer;
this.total = total;
}
public Quote(long quoteNumber, long total) {
this.quoteNumber = quoteNumber;
this.total = total;
}
public Quote() {}
}
Similarly, the Order class in the following listing is straightforward:
package co.uk.vsj.spring2.domain;
import java.io.Serializable;
public class Order implements Serializable {
private int id;
private long orderNumber;
private Customer customer;
private long total;
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public long getOrderNumber() { return orderNumber; }
public void setOrderNumber(long orderNumber) {
this.orderNumber = orderNumber;
}
public long getTotal() { return total; }
public void setTotal(long total) { this.total = total; }
public Customer getCustomer() { return customer; }
public void setCustomer(Customer customer) {
this.customer = customer;
}
public Order(int id, long orderNumber, Customer customer,
long total) {
this.id = id;
this.orderNumber = orderNumber;
this.customer = customer;
this.total = total;
}
public Order( long orderNumber, long total) {
this.orderNumber = orderNumber;
this.total = total;
}
public Order() {}
}
The RunSystem class tests these classes by creating customers, adding quotes, and then promoting a quote to an order. All of the logic in RunSystem resides within the execute() method. First it creates two customers:
public void execute() {
List<Customer> custList =
new LinkedList<Customer>();
System.out.println(
“\n\nAdding customers -----”);
// create the list of two customers
Customer cust1 =
new Customer(“001”,
“Sam Seltzer”, “225-2222”);;
Customer cust2 =
new Customer(“002”,
“Joanne Lowrey”, “323-3112”);
custList.add(cust1);
custList.add(cust2);
printReport(custList);
The printReport() method prints out all the customers, their quotes, and their orders by traversing the Customer objects and their contained lists. This method is used to verify that the object manipulation is successful.
After creating the customers, two quotes are created and added to the first, and one quote is added to the second customer. printReport() is called again to verify that the quotes are indeed added.
// add some quotes System.out.println( “Adding quotes -----”); cust1 = custList.get(0); cust2 = custList.get(1); Quote q1 = new Quote(1001,20); Quote q2 = new Quote(1002, 1990); Quote q3 = new Quote(1003, 33); cust1.addQuote(q1); cust1.addQuote(q2); cust2.addQuote(q3); printReport(custList);Finally, the first quote for the first customer is promoted to an order, and printReport() is called again to ensure that the first customer now has an order.
// promote a quote to an order System.out.println( “Promoting quote -----”); cust1 = custList.get(0); List<Quote> quotes = cust1.getQuotes(); q1 = quotes.get(1); cust1.convertToOrder(q1); printReport(custList); }
Testing the business domain objects
You will need JDK 1.5 to run this system. The code is tested against SUN JDK 1.5.0_09. In addition, you will need Ant 1.6.5 or later installed and running to use the Ant build scripts.From the source distribution, you will find two directories. The first directory, vsjspring, contains this initial version of the business objects. You can run this with “ant run” from the command line. You will see the Customer, Quotes, and Order created; and a quote promoted to an Order. See the example output:
run: [java] Adding customers ----- [java] Customer ID: 0 Account number: 001 Name: Sam Seltzer Phone: 225-2222 [java] Quotes : [java] Qrders : [java] Customer ID: 0 Account number: 002 Name: Joanne Lowrey Phone: 323-3112 [java] Quotes : [java] Qrders : [java] Adding quotes ----- [java] Customer ID: 0 Account number: 001 Name: Sam Seltzer Phone: 225-2222 [java] Quotes : [java] Quote ID: 0 , Quote number: 1001 , Total: 20 [java] Quote ID: 0 , Quote number: 1002 , Total: 1990 [java] Qrders : [java] Customer ID: 0 Account number: 002 Name: Joanne Lowrey Phone: 323-3112 [java] Quotes : [java] Quote ID: 0 , Quote number: 1003 , Total: 33 [java] Qrders : [java] Promoting quote ----- [java] Customer ID: 0 Account number: 001 Name: Sam Seltzer Phone: 225-2222 [java] Quotes : [java] Quote ID: 0 , Quote number: 1001 , Total: 20 [java] Qrders : [java] Order ID: 0 , Order number: 2002 , Total: 1990 [java] Customer ID: 0 Account number: 002 Name: Joanne Lowrey Phone: 323-3112 [java] Quotes : [java] Quote ID: 0 , Quote number: 1003 , Total: 33 [java] Qrders : BUILD SUCCESSFULOnce you’re satisfied with the working of this set of inter-related business objects, it’s time to transform them into persistent relational database entities.
Providing non-intrusive relational database storage
Given the RDBMS access technologies you may be familiar with, the various alternatives to do this transformation may include:- add JDBC code to access a set of tables that represents the objects
- create EJBs in a J2EE system to model the system of objects
Adding JPA annotations
You will now use Spring 2 to add relational database persistence in a non-intrusive and lightweight manner. Actually, the mechanism you will use is JPA (Java Persistence API), which is a standard component of the JEE 5 – a lightweight makeover of the vulnerable J2EE 1.x. Since the Spring framework led the lightweight revolution, it is not surprising that it works very well with JPA.Instead of requiring you to manually create the CREATE TABLE SQL statements, the table details can be specified using JSE 5 annotations. The annotations are used to provide hints to the JPA Object Relational Mapper (ORM). The ORM will generate the required SQL automatically, and work with its persistence provider to create the tables. An example will make it clear. The Customer class is annotated here:
@Entity
public class Customer implements Serializable {
private int id;
private String accountNumber;
private String name;
private String phone;
private List<Quote> quotes = new LinkedList<Quote>();
private List<Order> orders = new LinkedList<Order>();
@Id
@GeneratedValue(strategy = GenerationType.TABLE)
public int getId() { return id; }
public void setId(int id) { this.id = id; }
@Column(name = “ACCTNUM”, length=25)
public String getAccountNumber() { return accountNumber; }
public void setAccountNumber(String accountNumber) {
this.accountNumber = accountNumber;
}
public String getName() { return name; }
public void setName(String name) { this.name = name; }
@Column(name = “PHONE”, length=20)
public String getPhone() { return phone; }
public void setPhone(String phone) { this.phone = phone; }
@OneToMany(cascade = CascadeType.ALL, mappedBy = “customer”)
public List<Quote> getQuotes() { return quotes; }
public void setQuotes(List<Quote> quotes) { this.quotes = quotes; }
@OneToMany(cascade = CascadeType.ALL, mappedBy = “customer”)
public List<Order> getOrders() { return orders; }
...
The annotation for the properties such as name and account number can be made against the private field itself, or just before the getXXX() method for the field. JPA works with either field annotation or accessor method annotation.
The following table provides an explanation for each of the annotations used in the above listing:
| Annotations | |
| JPA annotation | Description |
| @Entity | Marks the class as an entity. This tells the JPA to match the class up with a table in the RDBMS. By default, the name of the class will be used as the name for the table. |
| @Id @GeneratedValue(strategy = GenerationType.TABLE) |
Specifies the field or attribute that will be used as the unique ID of an instance. In the relational database, this will become the primary key of the table. Best practice in database design recommends dedicating a non-data field for IDs. The @GeneratedValue() tag specifies that a database independent, table based, ID generation strategy should be used to generate values for this attribute. |
| @Column(name = “ACCTNUM”, length=25) | If you accept the existing field/attribute name as the corresponding column name in the RDBMS table you do not need to annotate the field/attribute because JPA will map it automatically. However, if you want to specify a specific column name (some relational databases may have column name restrictions) or data length, then you will need to annotate the field/attribute with @Column(). |
| @OneToMany(cascade = CascadeType.ALL, mappedBy = “customer”) | @OneToMany is used to annotate a field that relates to many occurrences of entities in another relational table. In this case, a Customer can have many Quotes and many Orders; there is a one-to-many relationship between Customer:Quotes and Customer:Orders. The CascadeType.ALL attribute tells JPA to cascade add, update, and delete operations to the subsidiary tables when the Customer table is modified. The mappedBy attribute contains the name of the column in the other table (Quote or Order) that will contain the primary key ID of this table. |
There are many other annotations, and each has a myriad of possible attributes. You should check the JPA specification (part of EJB 3 specification) for more information.
Mapping entity relationships
The annotations for the Quote and Order classes are similar, the Order class with JPA annotations is:@Entity(name=”orders”)
public class Order implements Serializable {
private int id;
private long orderNumber;
private Customer customer;
private long total;
@Id
@GeneratedValue(strategy = GenerationType.TABLE)
public int getId() { return id; }
public void setId(int id) { this.id = id; }
@Column(name = “ORDNO”)
public long getOrderNumber() { return orderNumber; }
public void setOrderNumber(long orderNumber) {
this.orderNumber = orderNumber;
}
public long getTotal() { return total; }
public void setTotal(long total) { this.total = total; }
@ManyToOne()
@JoinColumn(name=”CUSTID”)
public Customer getCustomer() { return customer; }
public void setCustomer(Customer customer) { this.customer = customer; }
public Order(int id, long orderNumber, Customer customer, long total) {
this.id = id;
this.orderNumber = orderNumber;
this.customer = customer;
this.total = total;
}
public Order( long orderNumber, long total) {
this.orderNumber = orderNumber;
this.total = total;
}
public Order() {}
}
The only new annotations to note in this listing are @ManyToOne(), and @JoinColumn(). @ManyToOne() specifies that this forms the “many” side of a one-to-many relationship. The @JoinColumn is similar to the @Column() annotation, but is used to tag a column that refers to a primary key in another table – in this case, the CUSTID column will be used to point back to the Customer table.
Creating a customer repository
With the objects annotated, let’s turn our attention to how the main code hooks up to Spring. First, there is a new CustomerRepository interface, this is the interface used to move Customer objects (and associated Quote and Order objects) to and from the persistence store (relational database). This interface is in the CustomerRepository.java file, and the core of the code is:@Transactional
public interface CustomerRepository {
public Customer
retrieveCustomerById(
int custid);
public Customer persistCustomer(
Customer cust);
public void deleteCustomer(
Customer cust);
public void updateCustomer(
Customer cust);
public List <Customer>
retrieveAllCustomers();
}
The @Transactional annotation is a Spring 2 transaction support annotation. It tells the Spring framework that the methods on these interfaces should be executed within a transaction (according to the default transaction settings). For more information on transaction control using the @Transactional annotation, see the Spring 2 documentation. This annotation is necessary because you want the data that you add or modify to be committed to the RDBMS. If the methods are run outside a transaction, data changes will not be committed automatically after successful method execution.
Setter injection of customer repository
Looking at the RunSystem code, first you will notice the use of setter injection to inject an implementation of the CustomerRepository into the RunSystem.public class RunSystem {
private CustomerRepository
customerRepos;
public void setRepository(
CustomerRepository repos) {
customerRepos = repos;
}
The execute() method of the RunSystem, shown in the following listing, is still largely identical to the original. Some major differences you will observe in this code are:
- The use of customerRepos.persistCustomer() to persist customer to the RDBMS respository
- The use of customerRepos.updateCustomer() to update the RDBMS with changes in Customer, or associated Ouote or Order information
- The printReport() method no longer takes a List<Customer> as argument. Instead, printReport() calls customerRepos.retrieveAllCustomers() to get the list of customers, with associated quotes and orders, from the RDBMS and then displays them:
public void execute() {
List<Customer> custList;
System.out.println(
“\n\nAdding customers -----”);
// create the list of two customers
Customer cust1 = new Customer(
“001”, “Sam Seltzer”, “225-2222”);;
Customer cust2 = new Customer(
“002”, “Joanne Lowrey”, “323-3112”);
customerRepos.persistCustomer(cust1);
customerRepos.persistCustomer(cust2);
printReport();
// add some quotes
System.out.println(
“Adding quotes -----”);
custList = customerRepos.
retrieveAllCustomers();
cust1 = custList.get(0);
cust2 = custList.get(1);
Quote q1 = new Quote(1001,20);
Quote q2 = new Quote(1002, 1990);
Quote q3 = new Quote(1003, 33);
cust1.addQuote(q1);
cust1.addQuote(q2);
cust2.addQuote(q3);
customerRepos.updateCustomer(
cust1);
customerRepos.updateCustomer(
cust2);
printReport();
// promote a quote to an order
System.out.println(
“Promoting quote -----”);
cust1 = custList.get(0);
List<Quote> quotes =
cust1.getQuotes();
q1 = quotes.get(1);
cust1.convertToOrder(q1);
customerRepos.updateCustomer(
cust1);
printReport();
}
Using ApplicationContext beans factory
The Spring framework itself is invoked through the main() method. Here, the ClassPathXmlApplicationContext class from the Spring framework is used to load the XML beans wiring configuration file, called vsjspringsystem.xml.One of the beans described in the configuration file is an instance of RunSystem called systemRunner. The getBean() method of the ApplicationContext is used to obtain the instance – this instance is created by the Spring framework according to the XML configuration. Once the RunSystem class instance is obtained, its execute() method is executed in the following code.
public static void main(String[] args) {
ApplicationContext bf = new
ClassPathXmlApplicationContext(
“/co/uk/vsj/spring2/config/
vsjspringsystem.xml”,
RunSystem.class);
RunSystem rs = (RunSystem)
bf.getBean(“systemRunner”);
rs.execute();
}
JPA DAO implementation
To tie JPA and Spring together, a Spring 2 library class called org.springframework.orm.jpa.support.JpaDaoSupport is used to implement the respository interface. This class implements a set of Data Access Objects (DAO) on top of the JPA APIs. This set of DAO provides a level of abstraction above the actual persistence mechanism (in this case JPA) and allows uniform access regardless of the actual database mechanism used. The following listing is code for the CustomerJpaRepository implementation, utilizing the JpaDaoSupport class.package co.uk.vsj.spring2.repository;
import java.util.List;
import org.springframework.orm.
jpa.support.JpaDaoSupport;
import
co.uk.vsj.spring2.domain.Customer;
public class CustomerJpaRepository
extends JpaDaoSupport
implements CustomerRepository {
public Customer retrieveCustomerById(
int custid) {
return getJpaTemplate().find(
Customer.class, custid);
}
public Customer persistCustomer(
Customer cust) {
System.out.println(
cust.getAccountNumber());
getJpaTemplate().persist(cust);
getJpaTemplate().flush();
return cust;
}
public void deleteCustomer(
Customer cust) {
getJpaTemplate().remove(cust);
}
@SuppressWarnings(“unchecked”)
public List<Customer>
retrieveAllCustomers() {
return getJpaTemplate().find(
lect e from Customer e”);
}
public void updateCustomer(
Customer cust) {
getJpaTemplate().merge(cust);
}
}
The JpaDaoSupport super class provides an implementation of the JpaTemplate interface, which can be obtained by calling getJpaTemplate(). The CustomerJpaRepository delegates the persist, delete, update and retrieve operations to the JPA DAO implementation. If you are familiar with JPA programming, you may wonder where the standard EntityManager is. The JpaTemplate implementation completely manages the acquisition and release of EntityManager instance, and the developer using JpaTemplate typically does not need to access the EntityManager directly. It is important to note, however, that it is possible to obtain the EntityManager instance directly within the Spring framework and use JPA API programming (bypassing JpaDaoSupport) if you wish to do so. See the Spring 2 documentation for more information.
Beans wiring configuration
The last source file that you will explore is the beans wiring configuration file. This is the vsjspringsystem.xml file. As mentioned earlier, this configuration file is all about the instantiation and wiring of components. The following is a step-by-step description of the beans and wiring that are performed.First, the schema and namespaces of the different Spring 2 features – such as transaction and AOP – are included as attributes in the <beans> tag. This Spring 2 configuration file always has root element <beans> since it contains the description of a whole bunch of beans:
<?xml version=”1.0” encoding=”UTF-8”?> <beans xmlns=”http://www. springframework.org/schema/beans” xmlns:xsi=”http://www.w3.org/ 01/XMLSchema-instance” xmlns:aop=”http://www. springframework.org/schema/aop” xmlns:tx=”http://www. springframework.org/schema/tx” xsi:schemaLocation=”http://www. springframework.org/schema/beans http://www.springframework.org/ schema/beans/spring-beans-2.0.xsd http://www.springframework.org/ schema/tx http://www.springframework.org/ schema/tx/spring-tx-2.0.xsd http://www.springframework.org/ schema/aop http://www.springframework.org/ schema/aop/spring-aop-2.0.xsd”>The next tag tells the Spring framework that transaction boundaries will be controlled by annotation. This enables the @Transactional annotation that we saw earlier on the CustomerRepository interface:
<tx:annotation-driven />Next, the RunSystem instance is created and an instance of CustomerRepository is injected into the class. This implementation of the CustomerRepository has a reference name of customerRepository – which is defined next:
<bean id=”systemRunner” class= ”co.uk.vsj.spring2.main.RunSystem”> <property name=”repository” ref=”customerRepository” /> </bean>The reference customerRepository is actually a CustomerJpaRepository instance. CustomerJpaRepository in turn inherits from JpaDaoSupport. The JpaDaoSupport class needs the injection of an EntityManagerFactory instance into its entityManagerFactory property:
<bean id=”customerRepository” class=”co.uk.vsj.spring2. repository.CustomerJpaRepository”> <property name= ”entityManagerFactory” ref=”entityManagerFactory”/> </bean>Spring provides a different EntityManagerFactory, here the LocalContainerEntityManagerFactoryBean is used. This bean has several properties that must be injected with other components. The table below lists the properties and the beans that are created and injected:
| Beans created and injected | |
| Property | Bean |
| dataSource | An HSQL data source, accessed via JDBC. The advantage of using HSQL is that it supports full JDBC access to an in-memory relational database. This enables us to create and test this example without setting up a standalone database server. By changing this data source, the same application can be easily adapted for MySQL, ORACLE, DB2, etc. |
| jpaDialect | JPA employs a plug-in model where different JPA providers can be plugged into JPA so individual JPA vendors may decide provide additional optimized access mechanisms. By specifying the jpaDialect that is used, it enables the potential use of these optimized access mechanisms by higher layers. In this case, you are using the reference JPA implementation, which can be considered a TopLinkJpaDialect. |
| jpaVendorAdapter | This is essentially a JPA implementation-specific “driver” for Spring. Spring’s JPA support currently works with most leading JPA implementations including the GlassFish reference implementation, TopLink, and Hibernate. |
| loadTimeWeaver | Specifies the load time byte code weaver to use for byte-code enhancement. Depending on the JPA vendor, the weaver that is used may be very different. An InstrumentationLoadTimeWeaver, in conjunction with a javaagent.jar, can be used for JPA implementations that may not have Spring-specific support. Some specialized JPA implementations for Spring may not require any load-time weaving at all. |
You can see the wiring of the above properties and beans in the next segment of the beans wiring configuration XML file.
<bean id=”entityManagerFactory” class=”org.springframework.orm.jpa. LocalContainerEntityManagerFactoryBean”> <property name=”dataSource” ref=”dataSource” /> <property name=”jpaDialect”> <bean class=”org.springframework.orm. jpa.vendor.TopLinkJpaDialect” /> </property> <property name=”jpaVendorAdapter”> <bean class=”org.springframework.orm. jpa.vendor.TopLinkJpaVendorAdapter”> <property name=”showSql” value=”true” /> <property name=”generateDdl” value=”true” /> <property name=”databasePlatform” value=”oracle.toplink.essentials. platform.database.HSQLPlatform” /> </bean> </property> <property name=”loadTimeWeaver”> <bean class=”org.springframework.instrument. classloading.InstrumentationLoadTimeWeaver” /> </property> </bean>The dataSource bean provides a hsqldb based in-memory data source for the entityManagerFactory.
<bean id=”dataSource” class=”org.springframework.jdbc. datasource.DriverManagerDataSource”> <property name=”driverClassName” value=”org.hsqldb.jdbcDriver” /> <property name=”url” value=”jdbc:hsqldb:mem:vsjspring” /> <property name=”username” value=”sa” /> <property name=”password” value=”” /> </bean>Last but not least, a transactionManager is defined. Spring’s JpaTransactionManager is used. Note that this transactionManager bean is instantiated but never directly wired into the property of any other bean. It is actually automatically injected into the properties of most beans that supports a transaction manager (such as the EntityManagerFactory or the <tx:annotation-driven> tag). By default, Spring will recognize beans that require the injection of a transaction manager, and will look for a bean to wire with the name “transactionManager” in the configuration file.
<bean id=”transactionManager” class=”org.springframework.orm. jpa.JpaTransactionManager”> <property name=”entityManagerFactory” ref=”entityManagerFactory” /> <property name=”dataSource” ref=”dataSource” /> </bean> </beans>
Trying out the Spring 2 system
Download the binaries for Spring 2. There are at least two selections available. The larger “with-dependencies” download is the best choice, since it includes the binaries of many other open source projects that you likely will need when you work with Spring 2.To try this Spring 2 version of the objects, you first need to be in the vsjspring2 directory. Then you need to edit the Ant script build.xml, and make sure you set the spring.root variable correctly. This should point to the directory where you have installed Spring 2.
From the vsjspring2 directory, type “ant build” to compile the project. Typing “ant run” will start and run the Spring JPA version of the system. Your output should be similar to:
[java] Adding customers ----- [java] Customer ID: 1 Account number: 001 Name: Sam Seltzer Phone: 225-2222 [java] Quotes : [java] Qrders : [java] Customer ID: 2 Account number: 002 Name: Joanne Lowrey Phone: 323-3112 [java] Quotes : [java] Qrders : [java] Adding quotes ----- [java] Customer ID: 1 Account number: 001 Name: Sam Seltzer Phone: 225-2222 [java] Quotes : [java] Quote ID: 3 , Quote number: 1002 , Total: 1990 [java] Quote ID: 4 , Quote number: 1001 , Total: 20 [java] Qrders : [java] Customer ID: 2 Account number: 002 Name: Joanne Lowrey Phone: 323-3112 [java] Quotes : [java] Quote ID: 5 , Quote number: 1003 , Total: 33 [java] Qrders : [java] Promoting quote ----- [java] Customer ID: 1 Account number: 001 Name: Sam Seltzer Phone: 225-2222 [java] Quotes : [java] Quote ID: 4 , Quote number: 1001 , Total: 20 [java] Qrders : [java] Order ID: 6 , Order number: 2002 , Total: 1990 [java] Customer ID: 2 Account number: 002 Name: Joanne Lowrey Phone: 323-3112 [java] Quotes : [java] Quote ID: 5 , Quote number: 1003 , Total: 33 [java] Qrders :The ant script actually spawns a separate JVM and starts it with the argument:
java -javaagent:c:\spring2\dist\ weavers\spring-agent.jar …This starts a JDK 5 instrumentation-based Spring agent, and hooks it into the JVM. This is currently required when using load time weaving with the reference JPA implementation (which has no built-in knowledge about Spring’s JPA support).
Tweaking logging output
When we wired up the TopLinkJpaVendorAdapter, the showSql property was set to true. This causes the reference JPA provider to print out the SQL statement that it is generating. You can set this property to false in order to remove the logging of the SQL statements. The generateDdl property was also set to true, this tells the JPA provider to create the actual tables in the RDBMS. If you are working with an already existing set of tables in the RDBMS, you will need to set this property to false.In the META-INF/persistence.xml file, which describes the JPA persistence unit, the toplink.logging.level property may be changed to control the level of logging. Changing the value from severe to fine will provide a very detailed level of JPA logging.
Conclusions
Spring 2 is a non-intrusive lightweight framework that can facilitate creation of componentized business applications. Using Spring’s support for JPA-based persistence, it is possible to add persistence support after the business objects have been fully implemented and tested. Through the use of byte-code enhancement and setter injection, capabilities such as persistence and transaction can be added via XML-based component configuration. Spring 2 can provide the same re-usable, maintainable, and loosely coupled component infrastructure as J2EE, but without all the overhead of creating and maintaining multiple files per component, and without a heavyweight do-everything container.Sing Li is a consultant, trainer and freelance writer specialising in Java, web applications, distributed computing and peer-to-peer technologies. His recent publications include Early Adopter JXTA, Professional JINI and Professional Apache Tomcat, all published by Wrox Press.
Inversion of Control and Dependency InjectionIf you read the Spring 2 literature, it is impossible not to see IoC (inversion of control) or DI (dependency injection) mentioned. Setter injection is a form of IoC/DI. IoC and DI are some terms used to describe this topsy turvy way put software components together. The code itself is not in control of which implementation is used, but the framework (or container) is. The program’s dependency is injected, after the code is written and compiled. Components are reusable through simple reconfiguration. |
Comments