Zip them up with compression filters
The compression API classes on the Java Platform are in the java.util.zip package. Some of the more frequently used classes are described below:- java.util.zip.GZIPInputStream – reads a stream that is compressed in the gzip format and decompresses it
- java.util.zip.GZIPOutputStream – writes the data out in compressed gzip format
- java.util.zip.ZipInputStream – reads a stream that is compressed in the zip format
- java.util.zip.ZipOutputStream – writes the data out in compressed zip format
- java.util.zip.InflaterInputStream – reads a stream that is in the “deflate” compression format
- java.util.zip.InflaterOutputStream – writes the data out in “deflate” compression format
Typical usage of these stream-based filter classes is shown in Figure 1, where the compression stream support classes act as a filter in a chain, either compressing or decompressing data as they flow through the filter. The source and sink of data are abstract streams and can be file, network, database, or other producer/consumers.
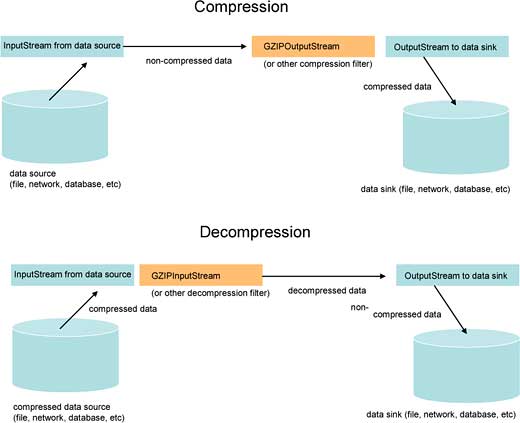
Figure 1: Output and input streams
Let’s try some hands-on examples and see how these actually work.
Compressing files
All of the code presented in this article has been tested against the SUN Java 6 SE Update 7 (6u7) JDK. Make sure you install the Java DB option when you install the JDK if you want to try out the compressed relational database example.In the first example, the ZipFileAccess class illustrates how to use the APIs to compress file and directory structures. ZipFileAccess is presented in the following listing.
package vsj.co.uk.zip;
import java.io.File;
...
import java.util.zip.ZipOutputStream;
public class ZipFileAccess {
public void ZipFileAccess() {
}
You can see the flow of the program in the main() method. First the c:\article.html file is compressed into c:\articlezip.zip.
public static void main(String args[])
throws Exception {
System.out.println("");
System.out.println("Compress file");
ZipFileAccess.compressFile(
"c:\\article.html",
"c:\\articlezip.zip");
System.out.println("");
Then the file c:\article.zip is decompressed and the output is written to c:\article.txt:
System.out.println("Decompress file");
ZipFileAccess.decompressFile(
"c:\\article.zip",
"c:\\article.txt");
System.out.println("");
Finally, the directory c:\testdir is zipped up into the archive c:\tree.zip.
System.out.println(
"Compress directory tree");
ZipOutputStream zout =
new ZipOutputStream(
new FileOutputStream(
"c:\\tree.zip"));
ZipFileAccess.compressFiles(
"c:\\testdir", "c:\\tree.zip",
new File("c:\\testdir"), zout);
zout.close();
}
Compressing a File
In the compressFile() method, a FileInputStream is created to read data from the input file. This data stream is not compressed. A FileOutputStream is then created to write data to the target zip file.To gzip all the output, an instance of GZIPOutputStream is created to wrap the FileOutputStream. Once wrapped, output written to the target file will be gzipped. You can see this wrapping in the listing of the compressFile() method:
public static void compressFile(
String infile, String outfile)
throws Exception {
System.out.println("Compressing " +
infile + " to " + outfile);
long byteCount = 0;
FileInputStream in =
new FileInputStream(infile);
GZIPOutputStream out =
new GZIPOutputStream(
new FileOutputStream(
outfile));
byte[] buf = new byte[16000];
int read;
while ((read = in.read(buf)) != -1) {
out.write(buf, 0, read);
byteCount += read;
}
in.close();
out.close();
System.out.println("read " +
byteCount + " bytes");
File zipped = new File(outfile);
System.out.println("wrote " +
zipped.length() + " bytes");
}
Decompressing a File
The decompressFile() method reads a file with gzipped content and writes the decompressed data into a target file. To accomplish this, first a FileInputStream is created to read the compressed data stream. The FileInputStream is then wrapped inside a new instance GZIPInputStream. Any data read through this wrapped assembly is now decompressed. To create the decompressed target file, a FileOutputStream instance is used. See the listing of decompressFile() for coding details:public static void decompressFile(
String infile, String outfile)
throws Exception {
System.out.println("Decompressing " +
infile + " to " + outfile);
long byteCount = 0;
GZIPInputStream in =
new GZIPInputStream(
new FileInputStream(infile));
FileOutputStream out =
new FileOutputStream(outfile);
byte[] buf = new byte[16000];
int read;
while ((read = in.read(buf)) != -1) {
out.write(buf, 0, read);
byteCount += read;
}
in.close();
out.close();
File unzipped = new File(infile);
System.out.println("read " +
unzipped.length() + " bytes");
System.out.println("wrote " +
byteCount + " bytes");
}
Creating a Zipped Directory Archive
Thus far, in the compressFile() and decompressFile() methods, you’ve only worked with a single stream of compressed data. The next method, compressFiles() method, can archive a complete directory of file into the zipped format. To accomplish this, it must have the ability to:- recurse directory structures to locate files/directories
- write ZipEntry to the output stream to tag the sub-streams representing the zipped files in the archive
The last three arguments to the compressFiles() method are unchanging when the method is called recursively. These arguments are shown in Table 1.
| Table 1: Last three arguments to compressFiles() | |
| Argument name | Description |
| outFileName | the absolute file name of the output file, this is passed down to ensure that the output file itself is not included in the resulting zip |
| inDir | specifies the top directory name that is being recursively archived |
| outStream | the main ZipOutputStream that compressed data is being written to |
The compressFiles() method is shown in the following listing:
public static void compressFiles(
String inFileName, String outFileName,
File inDir, ZipOutputStream
outStream) {
File inFile = new File(inFileName);
long bytesCount = 0;
long filesCount = 0;
FileInputStream entryIStream;
If the currently examined directory entry is a directory itself, the compressFiles() method is called recursively:
if (inFile.isDirectory()) {
File[] fList = inFile.listFiles();
for (int i = 0; i < fList.length;
i++) {
compressFiles(fList[i].
getAbsolutePath(),
outFileName, inDir, outStream);
}
}
else {
try {
Each directory entry is examined to make sure it is not the output file:
if (inFile.getAbsolutePath().
equalsIgnoreCase(outFileName)) {
// detect the output file name
// and skip if in director
return;
}
When a file to be zipped up is located via recursion, a ZipEntry is created and the file content is written to the ZipEntry together with its path name. Here, the path name for each entry is trimmed to ensure that it begins with the top directory being zipped (inDir). This is done to ensure that the resulting zip archive can be unzipped successfully from any directory.
System.out.println("Adding "
+ inFile);
bytesCount += inFile.length();
filesCount++;
String absPath =
inFile.getAbsolutePath();
String zipEntry =
absPath.substring(
absPath.indexOf(inDir
.getName()));
entryIStream =
new FileInputStream(inFile);
System.out.println(
"zip entry is " + zipEntry);
ZipEntry entry =
new ZipEntry(zipEntry);
outStream.putNextEntry(entry);
byte[] buf = new byte[16000];
int read;
while ((read =
entryIStream.read(buf)) != -1) {
outStream.write(buf, 0, read);
}
outStream.closeEntry();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
Running the File Compression Example
To test the ZipFileAccess, make sure you have:- c:\article.html file, this file will be compressed
- c:\article.zip file, this file will be decompressed
- c:\tesdir directory, this directory and its content will be zip archived
Compress file Compressing c:\article.html to c:\articlezip.zip read 48166 bytes wrote 13959 bytes Decompress file Decompressing c:\article.zip to c:\article.txt read 17765 bytes wrote 48067 bytes Compress directory tree Adding c:\testdir\first\article.html zip entry is testdir\first\article.html Adding c:\testdir\first\third\article.html zip entry is testdir\first\third\article.html Adding c:\testdir\second\article.txt zip entry is testdir\second\article.txtAfter a successful run, you should see:
1. c:\articlezip.zip compressed file 2. c:\article.txt decompressed file 3. c:\tree.zip zip archiveYou can use a zip utility, such as the open source 7-zip, to open up the c:\tree.zip archive. Figure 2 shows 7zip displaying the content of c:\tree.zip.
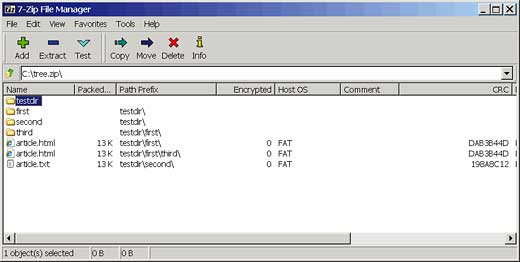
Figure 2: The content of the zip directory
Working with compressed network streams
When you apply the compression API to data transferred over a network, you save valuable transmission time – allowing you to transfer more data with the same bandwidth allocation.The ZipNetFetch class illustrates how to work with compressed network streams. The following example shows how to request and process compressed network data stream with the help of a standard web server.
Almost all modern web servers can be configured to support compressed data streams. The client (most of the time browsers) can specifically request a compressed data stream via the Accept-Encoding HTTP request header. For example, a request header of:
Accept-Encoding: gzip…tells the web server that the client is able to decode gzip streams, and the server should transmit data via gzip stream if possible.
This example, the ZipNetFetch class:
- reads an existing VSJ article from the VSJ web server, requesting a gzip stream; and then stores the resulting compressed stream in c:\article.zip file
- reads the same article, requesting a deflate stream; and then stores the resulting compressed stream in c:\article2.zip
- reads the same article without requesting compression; and then stores the resulting web page in c:\article.html
package vsj.co.uk.zip;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class ZipNetFetch {
public static void main(String args[])
throws Exception {
ZipNetFetch.CompressedURL curl =
new ZipNetFetch.CompressedURL(
new URL("http://www.vsj.co.uk/
articles/display.asp?id=749"));
System.out.println("");
System.out.println(\
"Trying compression gzip");
ZipNetFetch.
readURLIntoFileTryCompression(
curl, "gzip", "c:\\article.zip");
System.out.println("");
System.out.println(
"Trying compression deflate");
ZipNetFetch.
readURLIntoFileTryCompression(
curl, "deflate",
"c:\\article2.zip");
System.out.println("");
System.out.println(
"No compression");
ZipNetFetch.
readURLIntoFileTryCompression(
curl, "", "c:\\article.html");
}
The CompressedURL helper class
The CompressedURL class contains code that manages the HTTP connection to the web server. This includes getCompressedStream() method which sends the Accept-Encoding request header. The actual encoding used by the server to transmit the data is stored in the mCompression member variable. This encoding is retrieved from the response data stream returned by the server.public static class CompressedURL {
private URL mURL = null;
private String mCompression = null;
public CompressedURL(URL url) {
mURL = url;
}
public String getCompression() {
return mCompression;
}
public InputStream
getCompressedStream(String
compression) throws Exception {
HttpURLConnection conn =
(HttpURLConnection)
mURL.openConnection();
conn.setRequestProperty(
"Accept-Encoding", compression);
conn.connect();
mCompression =
conn.getContentEncoding();
if (mCompression == null) {
mCompression = "";
}
return conn.getInputStream();
}
} // of CompressedURL class
The writeInputStreamToFile() method takes an InputStream and writes the content of the stream to a specified file. You have seen similar code in the previous example. Of course, if you are actually using this in production code, and the InputStream is compressed, you can readily wrap it in a GZIPInputStream instance to decompress it.
writeInputStreamToFile() is shown in the following listing:
public static long
writeInputStreamToFile(
InputStream inp, String filename)
throws Exception {
long bytecount = 0;
FileOutputStream out =
new FileOutputStream(filename);
byte[] buf = new byte[16000];
int read;
while ((read = inp.read(buf)) != -1) {
bytecount += read;
out.write(buf, 0, read);
}
inp.close();
out.close();
return bytecount;
}
The readURLIntoFileTryCompression() method wraps several common step to simplify the repeated logic in the main() method. It also prints the number of bytes read in the stream and the time it takes to read the stream.
public static void
readURLIntoFileTryCompression(
ZipNetFetch.CompressedURL url,
String compression, String filename)
throws Exception {
long startTime =
System.currentTimeMillis();
InputStream inp =
url.getCompressedStream(
compression);
if (url.getCompression().equals(
compression)) {
long bytes = ZipNetFetch.
writeInputStreamToFile(
inp, filename);
System.out.println(bytes +
" bytes in " +
(System.currentTimeMillis() -
startTime) / 60.0fv
+ " seconds");
} else {
System.out.println(compression +
" is not supported.");
}
}
}
Testing the compressed network stream example
Before you try the ZipNetFetch example, make sure you are connected to the Internet and can access the www.vsj.co.uk server.The following is the output from a sample run of the ZipNetFetch example:
Trying compression gzip 17821 bytes in 21.366667 seconds Trying compression deflate 17731 bytes in 6.766667 seconds No compression 47995 bytes in 5.2 secondsThe time measured is a little unexpected. The first time the server is accessed took the longest, since the HTTP 1.1 protocol keeps the TCP connection alive for the second and third requests. The important thing to note is that the actual length of the compressed stream is substantially shorter.
The test will create c:\article.zip, c:\article2.zip, and c:\article.html. You can modify ZipFileAccess to unzip these files and verify their content.
Compressed fields in relational databases
The same compression API can be used in conjunction with JDBC to store and retrieve compressed data. In this final example, you will populate a BLOB field in a relational database table with a compressed version of the article.html file.See the ZipDBAcccess class listing below for the example code:
package vsj.co.uk.zip;
import java.io.File;
...
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
public class ZipDBAccess {
public ZipDBAccess() {
}
private Connection conn;
The main() method orchestrates the data access. First, the setupJavaDB() method is called to start Java DB and create the relational database table if it does not exist already. Then, the addRecord() method is called to add a record to the database with the compressed field. Finally, the showRecord() method is called to query the newly inserted record, and access the content of the compressed field.
public static void main(String args[])
throws Exception {
ZipDBAccess dba = new ZipDBAccess();
// create the database and the table
dba.setupJavaDB();
dba.addRecord();
dba.showRecord();
}
}
Connecting to Java DB
The setupJavaDB() method performs the following steps:- Starts Java DB, the Apache Derby relational database, in the embedded mode
- Creates a database called vsjdb in the c:\db directory if it does not already exist
- Obtains a connection to the database
- If not existing already, creates the article table, containing a BLOB (Binary Large Object) file that will hold the compressed content
- If the article table already exists, the code will delete all the records in the table
public void setupJavaDB()
throws Exception {
conn = DriverManager.getConnection(
"jdbc:derby:c:\\db\\vsjdb;
create=true");
String createCmd =
"create table articles(name
varchar(32) not null primary key,
zipcontent blob(100K))";
Statement stmt =
conn.createStatement();
try {
// always try to create table
stmt.execute(createCmd);
} catch (SQLException ex) {
// already exists - drop all records
String deleteCmd =
"delete from articles";
stmt.executeUpdate(deleteCmd);
}
}
The database table created is named articles and contains the fields shown in Table 2.
| Table 2: Articles fields | |||
| Field Name | Data Type | Length | Description |
| Name | varchar | up to 32 chars | Name of the article stored |
| zipcontent | BLOB | up to 100k bytes | A gzipped copy of the of the article |
Storing compressed data in a BLOB field
The addRecord() method reads the content of the c:\article.html file, compresses it, and then stores the compressed data into the zipcontent field of a new record in the articles database. This process is not entirely straightforward.In order to create the compressed data, the code must first read the article.html file via a FileInputStream. The data from the FileInputStream is written to an instance of GZIPOutputStream in order to create the compressed data stream. So you have an instance of GZIPOutputStream ready, but the JDBC API to write a stream of data into a BLOB field requires an instance of InputStream to read from. An adapter must be constructed to change the GZIPOutputStream into an InputStream. Figure 3 shows this situation, where a PipedInputStream and its corresponding PipedOutputStream are used to create an adapter, effectively converting the GZIPOutputStream into an InputStream.
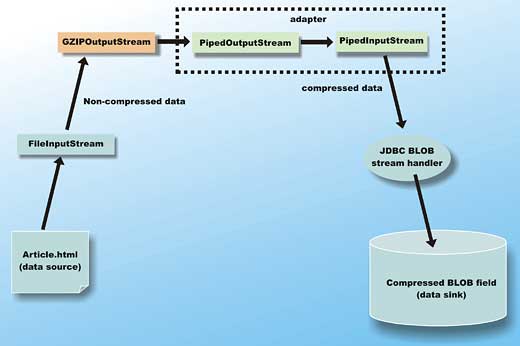
Figure 3: Converting from output to input
The data flow consists of:
- A PipedInputStream instance is created (named “in”), and will be passed to the JDBC API to update the field
- A PipeOutputStream is constructed from the PipedInputStream, then wrapped in a GZIPOutputStream named “out”
- Uncompressed data is read from the FileInputStream fstream, and written to the GZIPOutputStream
- A new thread is created to perform step 3 concurrently with the reading of the adapter PipedInputStream by the JDBC API
public void addRecord() throws
Exception {
// store a compressed records
File inFile =
new File("c:\\article.html");
final FileInputStream fStream =
new FileInputStream(inFile);
PipedInputStream in =
new PipedInputStream();
final GZIPOutputStream out =
new GZIPOutputStream(
new PipedOutputStream(in));
new Thread(new Runnable() {
public void run() {
int byteCount = 0;
byte[] buf = new byte[1024];
int read;
try {
while ((read = fStream.read(
buf)) != -1) {
out.write(buf, 0, read);
byteCount += read;
}
System.out.println(
"original length is " +
byteCount);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
fStream.close();
out.close();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}).start();
PreparedStatement stmt = conn
.prepareStatement(
"INSERT INTO articles (name,
zipcontent) values(?, ?)");
stmt.setString(1, "article.html");
stmt.setBinaryStream(2, in);
stmt.executeUpdate();
stmt.close();
in.close();
}
Reading data from a compressed BLOB
The showRecord() methods uses the JDBC API to fetch the content of the compressed BLOB field from the relational database. The SQL query executed is:select * from articles where name='article.html'The execution result of this query is accessed via a ResultSet instance, returned from the JDBC executeQuery() API. The ResultSet.getBlob() method can be conveniently used to access the value from a BLOB type data field. In this case, the code simply notes the length of the resulting field and prints it.
If you need to access the content of the Blob as a stream, you can use the blob.getBinaryStream() method. Since the content of this stream is compressed, it can be decompressed by wrapping it with a GZIPInputStream().
The showRecord() method is shown in the following listing:
public void showRecord() throws
Exception {
PreparedStatement stmt =
conn.prepareStatement(
"select * from articles
where name='article.html'");
ResultSet rs = stmt.executeQuery();
rs.next();
Blob blob = rs.getBlob("zipcontent");
System.out.println("the length of th
compressed field is "
+ blob.length());
/* uncomment this to see uncompressed
field content
GZIPInputStream gStream =
new GZIPInputStream(
blob.getBinaryStream());
byte[] buf = new byte[1024];
int read;
while ((read = gStream.read(buf))
!= -1) {
System.out.write(buf, 0, read);
}
*/
}
Running the compressed database field example
Make sure that derby.jar is in your classpath when you compile ZipDBAccess. Apache Derby (derby.jar) is part of Java DB, distributed standard as a part of Java SE 6. Depending on your installation, the file may be located in the C:\Program Files\Sun\JavaDB\lib directory.You also need to create c:\db directory to house the database that will be created by the example.
When you run ZipDBAccess, you should see the output similar to the following:
original length is 48166 the length of the compressed field is 13959Here, the code has created the articles table, read the articles.html file and noted its original length. It then compressed the data, and stored it as a BLOB field in the articles RDBMS table.
Finally, it uses JDBC API to query for the compressed BLOB field, and prints out its length.
If you want to see the uncompressed content fetched and decoded directly from the database field, just uncomment the following section of code in the showRecord() method:
GZIPInputStream gStream =
new GZIPInputStream(
blob.getBinaryStream());
byte[] buf = new byte[1024];
int read;
while ((read = gStream.read(buf))
!= -1) {
System.out.write(buf, 0, read);
}
Conclusions
Compressed data takes up less space and requires less time to transmit across a network, often resulting in significant cost savings.Modern-day CPU hardware is powerful enough that the additional computation required for compression and decompression is typically minimal. The Java platform’s built-in compression APIs come in handy whenever you need to compress data and are readily usable on files and network transmitted data, as well as on data stored in relational databases.
Sing Li has been writing software, and writing about software for twenty plus years. His specialities include scalable distributed computing systems and peer-to-peer technologies. He now spends a lot of time working with open source Java technologies.
Comments