This article discusses anti-patterns based on Hibernate and JPA to highlight daily problems when using O/R mappers, and provides some tips and tricks on how to prevent these problems. O/R mappers are part of the Java platform, at the latest since the standardization by the Java Persistence API (JPA) – and they are really popular. Hibernate is probably the most popular O/R mapping framework and is also the basis for the JPA implementation of the JBoss Application Server. Its easy-to-use programming interface and the easy usage of the framework has contributed to the success of Hibernate. The Spring framework also offers extensive support for Hibernate and JPA with lots of efficient help functions and templates.
The simplicity of the entrance into the world of O/R mapping however gives a wrong impression of the complexity of these frameworks. Working with more complex applications you soon realize that you should know the details of framework implementation to be able to use them in the best possible way. In this article, we describe some common anti-patterns which may easily lead to performance problems.
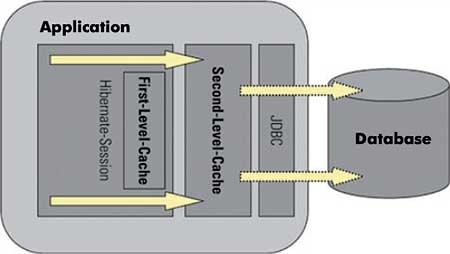
Hibernate first and second level cache
Anti-pattern: Inefficient fetching strategies
A basic function of Hibernate/JPA is the definition of associations between objects, for example the relation “person has addresses”. Whenever a person is loaded, the so-called fetching strategy determines whether the addresses are loaded instantly – eager loading – or at a later time – lazy loading. If no fetching strategy is specified, the associations are loaded lazily, which means that these are only fetched from the database (or from the cache) when someone accesses them. If it is clear that the addresses of the person are accessed before loading an object, however, it would be better to load the person including addresses with an SQL statement. If the addresses are loaded with an eager fetching strategy, Hibernate creates an outer-join query to reduce the number of statements.In practice it is often difficult to define which objects should be loaded lazily and which eagerly, as the objects are used in different contexts, but is only possible to configure a certain fetching strategy. Especially for multilevel relations, the configured fetching strategies may become confusing and the number of statements which are executed when an object and its data are accessed may be hard to predict. The usage of annotations can make it easier to keep things clear; however, it will not solve the problem of multiple usage scenarios. In most cases it is advisable to define all associations as lazy first. Then, with a solution like dynaTrace, you can analyze how many statements are executed for certain usage scenarios. Based on this information the fetching strategies can be adjusted. Alternatively, find methods can be defined in the DAOs for optimizing the performance for certain actions. These methods load object trees with an optimized HQL/EJB-QL-query. Using the Generic DAO Pattern for this minimizes the code of a DAO which has to be programmed.
Anti-pattern: Flush and Clear
Hibernate administers the persistent objects within a transaction in the so-called session. In JPA, the EntityManager takes over this task. In the following, the term “EntityManager” will also be used as a synonym for the Hibernate session, as both have a similar interface. As long as an object is attached to an EntityManager, all changes to the object will be synchronized with the database automatically. This is called flushing of the objects. The point in time of the object synchronization with the database is not guaranteed – the later a flush occurs, the more optimizing potential has the EntityManager, because e.g. updates to an object can be bundled to prevent SQL statements.If you call clear, all currently managed objects of the EntityManager will be detached and the status is not synchronized with the database. As long as the objects are not explicitly attached again, they are standard Java objects, whose change does not have any effect on the data base. In many applications that use Hibernate or JPA, flush() and clear() are frequently called explicitly, which often has fatal effects on performance and maintainability of the application. A manual call of flush() should be prevented by a clear design of the application and is similar to a manual call of System.gc() which requests a manual garbage collection. In both cases, a normal, optimized operation of the technologies is prevented. For Hibernate and JPA this means that generally more updates are made than necessary in the case the EntityManager would have decided about the point in time.
The call of clear(), in many cases preceded by a manual flush(), leads to all objects being decoupled from the EntityManager. For this reason you should define clear architecture- and design guidelines about where a clear() can be called. A typical usage scenario for clear() is in batch processing. Working with unnecessary extensive sessions should be prevented. Apart from that, this should be noted in the Javadoc of the method explicitly, otherwise the application could show some unpredictable behaviour if the call of a method can lead to the deletion of the complete EntityManager context. This means that the objects must be re-inserted into the context of the EntityManager. Normally, the status of the objects has to be re-imported from the database for this. Depending on the fetching strategies, there are cases in which the status of the objects must be read manually to have all associations attached again. In the worst case, even modified object data will not be saved permanently.
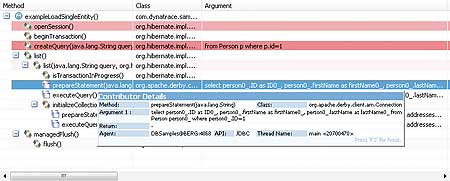
Prepared statement of an HQL query without parameters
Anti-pattern: Insufficient caching
For databases, the following applies to all levels: the best database accesses are those that do not have to be carried out. For this, caches are used within the database and also in Hibernate and JPA. Caching is relatively complex and one of the most misunderstood concepts of Hibernate. There are three different caches:- First level cache: always active and relates to a unit of work, i.e. mostly to a service call as it is attached to the current session.
- Second level cache: can be configured for certain entities. In this case, the objects are deposited in a cross-transaction cache. The key to this deposit is the primary key of the entity. The cache can be configured cluster-wide or within a JVM.
- Query cache: stores the result of an HQL/EJB-QL query in a cache. For this, only the primary keys of the result objects are stored which are then loaded via second level cache. Thus the query cache works only together with the second level cache.
If all entities in the cache are modified, too, you have to decide how important the consistency of the data in the cache with the database really is. Hibernate supports transactional caches for which each update on the cache is stored permanently directly in the database, but also less restrictive algorithms which control the validity of data based on timestamps. Depending on the frequency of modifications and the data consistence requirements, the gain in performance of the second level caches must be evaluated differently. An exact analysis of the access behaviour with the help of a profiler or monitoring tool is thus very helpful for the correct configuration of the second level cache.
Some other points must be observed, however, if the second level cache is used, because one might be astonished that even with active second level cache there can still be queries. The entities in the second level cache are identified via their primary key. This also means that only those queries are read from the cache which read an entity via primary key. If you have, for example, a class named person that can be identified via a unique, consecutive number as primary key, only those queries can be optimized by the second level cache which read a person via this consecutive number. If person is searched via family and first name, these queries would go directly to the database past the second level and there would not be any performance savings though a second level for person exists. To be able to use a cache for the search via first and last name, the query cache must be activated for the query. In this case all primary keys of person from the query output are stored in the cache. If a new search is carried out for the same name, the primary keys are read from the query cache and a query is send to the second level cache which then gives the results back from the cache. This is the only way to prevent direct database queries.
Another pitfall is that the data in the second level cache are not stored as objects, but in a so-called dehydrated form. The dehydrated form is a sort of serialization of the entities. If an entity is read from the second level cache, it must be “rehydrated”, that is de-serialized. If huge amounts of query outputs are given back, which are all in the second level cache, this may lead to performance problems. Each object must be read from the cache and be de-serialized. The advantage is that each transaction gets back its own object instance from the cache, which prevents concurrency problems. This means that the second level cache is thread-safe. Especially for key values which are accessed read-only, the second level cache can be slower compared to a normal object cache. It is a good idea to analyze the application thoroughly and, if necessary, to put the key objects in a cache above the database access layer. The details of the different cache configurations can only be sketched here but the correct usage of the different caches is absolutely necessary, especially for frequently used applications, to achieve a good performance.
Anti-pattern: Key to success
There is much debate about using the correct primary keys. Is it wise to use so-called surrogates, whose primary key is a system-generated key (e.g. a concurrent number of the type long) or logic keys which consist of logic attributes of the entity? It is important to understand which effects the choice of the key has on the performance of the system. A surrogate has the big advantage that it is relatively simple and consists, most of the time, only of a numeric attribute so when checking the entities for consistency, only a numeric comparison operation has to be performed. Especially for JPA and Hibernate entities are frequently compared, for example a check is performed to discover whether an entity is in one of the caches. A logic key can consist of a huge amount of attributes (especially if it is inherited across tables) with different data types. This means that the comparison of two entities is a lot more complex because the entities are the same if all attributes are identical. For logic keys a lot of attention should be paid to the equals()- and hashCode()-methods of the primary keys – a performance bottleneck might be prevented this way.Anti-pattern: Explicit queries
The simplest option for queries in Hibernate is the usage of the query()-method to pass on the query as a string. Hibernate (or JPA) offers the possibility of using parameters and relating them explicitly to values. With Hibernate this approach makes sense for queries which are repeated several times. There seems to be no overhead for a single query. If you look at the execution path of a Hibernate query you will see that Hibernate uses a PreparedStatement for each query. This uses the HQL query as the basis for generating the SQL query. If no parameters are used, a PreparedStatement with the explicit query is generated. Of course this PreparedStatement cannot be re-used, except for the very same dataset. Thus, unnecessary resources (most of the time cursors) are consumed by the database. What’s more, the statement cannot be re-used by other transactions. Thus it is recommended always to use parameter-based queries to be able to utilize the advantage of prepared statements on the layer below in an optimal way.Conclusion
In this article, the potential pitfalls and anti-patterns in the usage of Hibernate and JPA have only been sketched out. However it demonstrates that using Hibernate and JPA is not as simple as the API might lead us to believe. For a good performance, the frameworks must be configured and applied correctly. Using profilers and monitoring solutions during development is important because potential bottlenecks can be identified early. This way, we can turn the blackbox O/R mapper into a whitebox.Alois Reitbauer is Senior Performance Architect at dynaTrace Software.
Mirko Novakovic is co-founder of codecentric GmbH. He specialises in the areas of performance tuning, Java-EE-architectures and open source frameworks.
Comments