Aspect Oriented Programming, or AOP, is a method of development complementary to Object Oriented Programming. Like OOP, AOP stresses the idea of code reuse to reduce clutter and confusion. However, AOP is different in the sense that it encourages the reuse implementations to be built in a manner that allows the functionality to be inserted anywhere into existing code.
In .NET, the most elegant manner of allowing code to be added to existing code is through the use of Attributes. PostSharp, a leading AOP tool for .NET, provides a developer the ability of encapsulating repetitive code into custom Attribute classes. In PostSharp lingo, these classes are typically referred to as various types of Aspect classes.
In this article, you will see how AOP and PostSharp can be used to solve
- Common tasks such as logging or code timing
- More complex scenarios such as transaction management and thread safe WPF GUI updates.
Finally, the method by which PostSharp changes compiled code will be examined to give some clarity into how the product functions (at a very high level).
Requirements
To follow along with this article, you will need the following installed:
- Visual Studio 2010 or later and .NET 4.0 or higher. Visual Studio Express will allow for PostSharp’s post-compilation support so the Aspects you write will work, but the PostSharp IDE extensions are not available for Express
- PostSharp 2.1. You can download it from http://www.sharpcrafters.com/postsharp/download
If you prefer to not install the full PostSharp installation, it is available as a NuGet package and can be obtained by typing Install-Package PostSharp in the package command console window (the NuGet command line embedded into Visual Studio) - The code for this article.
The Metaphor of Aspects
Though the requirements of each application vary by leaps and bounds, some truths remain consistent across each application implementation:
- Functionality needs to be logged to a debugger during development.
- Execution timing needs to take place to find performance bottlenecks.
- Database rules need to be implemented using Transactional Processing so that orphan data will be mitigated and business rules applied.
- GUI code sometimes results in the requirement of multi-threaded code so that the user interface remains responsive while background processes execute
Sometimes shortcomings in frameworks promote the need for utilitarian code that more serves the coder than the business stakeholder. Somehow, that utilitarian code finds a way to weave itself into the real, core application code – the stuff the client paid us to build, not the stuff we needed to build to make sure we were doing it properly.
Those truths are evident to such a degree in every application that they’re believed to be aspects consistent in each application and on each project. These abstract aspects are the areas where true reuse can provide exponentially more concise application code. That’s where AOP comes in, as it allows for the application of these reusable components when and where appropriate rather than require that code be intermingled with the core business functionality implementation.
Exemplifying Common Issues in Programming
The best way to demonstrate the effectiveness of a particular technology is to use it or to observe its usage in the wild. AOP is best understood when seen in context – improving and clarifying application code. For that purpose, this article will break an existing codebase apart. Upon reconstruction the code will be improved through the creation of Aspects whenever code exists that could be reused in other areas. Not just typical reuse in the manner of componentized objects, but in the way those objects will be applied to their target.
The target application being re-engineered provides a user the ability to provide basic personal information for persistence in a SQL Server database. The single form of this application at run-time is below. The code for this article provides two versions of this form. Before.xaml contains the code before refactoring and After.xaml contains the code refactored to use Aspects.
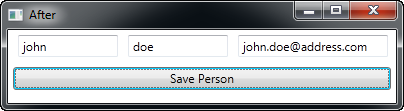
The database in which the data will be stored is relatively simple. A user can have multiple email addresses, and there will be a unique constraint placed on the email address value for the email table. Some architectural expectations are also in place; the code will need to provide detailed logging output at debug time and each method will need to be timed and the timing output to the log as well, so that bottlenecks in performance can be observed and fixed.
Code Copying and Reuse vs Automatic Execution
The architectural requirements introduce the probability that utilitarian code – logging, timing, transaction management, threading checks – will be intermixed with actual application code. This sample application actually has more technical and architectural requirements than it does business requirements. With that in mind, the probability for copy-and-paste coding techniques is quite high. Consider the basic architectural requirement of timing; each method needs to be timed. This means that every method will have code in it that creates, starts, and stops a Stopwatch instance, and reads the elapsed time so that it can be written to the debug window. The code below shows one adequate, though not necessarily elegant, method of achieving this requirement.
private void OnTransactionButtonDemoClicked(object sender, RoutedEventArgs args)
{
new Action<Stopwatch>((watch) =>
{
this.WriteToLog("Handling new person form submission");
var f = this.firstName.Text;
var l = this.lastName.Text;
var e = this.emailAddress.Text;
new Thread(new ThreadStart(() =>
{
this.SaveNewPerson(f, l, e);
})).Start();
this.WriteToLog("Finished handling new person form submission");
this.WriteToLog(
string.Format("{0} took {1}ms to execute",
new StackTrace().GetFrame(1).GetMethod().Name,
watch.ElapsedMilliseconds));
}).Invoke(Stopwatch.StartNew());
}
All of the other methods in the application need to be independently timed. So, a developer will find it easy and natural to copy and paste the code as is demonstrated above in another method within the application.
The problem with this approach, is that it’s not reusable, or at least not without creating a separate method just to wrap the real work being done. Every application requires a little logging to understand performance and behavior. This methodology – requiring the wrapping of code in a clock and logging the results of performance each and every time – dictates that extremely repetitive code be written. This repetitive code also has little to do with the intent of the entire code base, so why not isolate it in an independent module that can be applied when it is needed – that’s the provision AOP allows.
void SaveNewPerson(string firstName, string lastName, string email)
{
new Action<Stopwatch>((watch) =>
{
#Region Save to the database
}).Invoke(Stopwatch.StartNew());
}
Logging, the other basic architectural requirement, introduces a single method to streamline logging, but doesn’t really make it not only reusable, but automatic. As it stands now, explicit calls must be made to the method, rather than execution of the method just happen automatically. So it provides a decent example of reuse, but is still tied to the code using it because that code must make calls to it. This code is reusable, but isn’t automatic, and still requires coupling from within the code that will make use of it.
void WriteToLog(string message)
{
Debug.WriteLine(message);
}
These issues, as well as those examined in a moment, will be solved by creating custom Aspects to do the work these utility methods provide to solve the application’s functional aspects.
Repetitive Code
Opportunities for refactoring aren’t limited to simple topics such as logging and timing. Exception management, external thread GUI update headache resolution, and transaction management are other areas. For each of these, some level of complexity exists, but some level of repetitiveness exists, too. Transaction usage code needs to be weaved in any time multiple tables will be updated in any database, especially when constraints exist on the data as they do in the case of this example application, which intentionally prohibits email address re-use.
From the SQL code below (create_people_table.sql in the download – Ed), you’ll see that two tables are being created. A constraint exists on one of the tables, to prevent duplicate email addresses being persisted.
create table Person
(
Id int identity(1,1) primary key,
FirstName nvarchar(32),
LastName nvarchar(32)
)
create table EmailAddress
(
Id int identity(1,1) primary key,
PersonId int,
Email nvarchar(255) unique
)
So that this constraint is enforced, the need exists for transactional code like that below to be executed on the database. With a transaction in place, errors that occur – such as the attempt to save and already-saved email address – can easily be rolled back and potential data problems averted.
#region Save to the database
using (var cn =
new SqlConnection(ConfigurationManager
.ConnectionStrings["testing"].ConnectionString))
{
using (var c = cn.CreateCommand())
{
if (cn.State != ConnectionState.Open) cn.Open();
c.Transaction = cn.BeginTransaction();
try
{
c.CommandText = "insert into person values(@f,@l) select @@identity";
c.Parameters.AddWithValue("@f", firstName);
c.Parameters.AddWithValue("@l", lastName);
var personId = c.ExecuteScalar();
c.CommandText = "insert into emailAddress values(@p,@e)";
c.Parameters.AddWithValue("@p", personId);
c.Parameters.AddWithValue("@e", email);
c.ExecuteNonQuery();
c.Transaction.Commit();
this.UpdateStatus("Success");
}
catch (Exception ex)
{
this.WriteToLog("Exception during person-saving transaction: " + ex.ToString());
c.Transaction.Rollback();
this.results.Text = "Error";
}
}
}
#endregion
Even abstract Aspects such as transaction management add a series of method calls such as those highlighted above to create and use the transaction in with the otherwise functionally core application logic. The transaction code doesn’t really serve the code aside from enforcing some arbitrary rule set.
Refactoring with Aspects
Even in such a small application as this then, common tasks and basic application requirements can quickly introduce a lot of smelly code. Fortunately, as we’ve discussed, we can use Aspect classes to refactor the code and deodorize it.
Logging and Timing
The first choice for most AOP discussions is to use it to perform the basic logging requirements of an application. This quintessential example does a few very simple pieces of work.
- The Aspect stops the execution of a method
- It runs its own functionality.
- The method executes (or errors) and completes.
- Once that happens the Aspect class runs even more code.
This code eventually whittles all of the logging code out of the application and into the Aspects which are linked to the methods with Attributes as we’ll see later. This keeps the logging separate from the code application business logic.
Note that it is a good idea to handle exceptions within Aspects, because code that explodes within an Aspect will cause a run-time exception to be thrown. The code in the Aspect below is logging to the Debugger, so the chances of an exception being thrown at run-time is virtually negligible. Just be careful and handle potential exceptions as you would in other code (or just use another Aspect that handles exceptions!).
[Serializable]
public class LoggingAspect : OnMethodBoundaryAspect
{
public override void OnEntry(MethodExecutionArgs args)
{
Debug.WriteLine(
string.Format("{0} Started",
new StackTrace().GetFrame(1).GetMethod().Name)
);
base.OnEntry(args);
}
public override void OnExit(MethodExecutionArgs args)
{
Debug.WriteLine(
string.Format("{0} Exited",
new StackTrace().GetFrame(1).GetMethod().Name)
);
base.OnExit(args);
}
}
Note how the logging class, and the timing class below, both inherit from the OnMethodBoundaryAspect type. That type, explained in far greater detail in the extensive online PostSharp documentation, provides opportunities to intercept the code of a method and to execute code prior to it, after it, on success only, or should it throw an exception during its execution.
Likewise, the timing functionality can also be extracted into its own Aspect class.
[Serializable]
[MulticastAttributeUsage(MulticastTargets.Method)]
public class TimingAspect : PostSharp.Aspects.OnMethodBoundaryAspect
{
[NonSerialized]
Stopwatch _stopwatch;
public override void OnEntry(PostSharp.Aspects.MethodExecutionArgs args)
{
_stopwatch = Stopwatch.StartNew();
base.OnEntry(args);
}
public override void OnExit(PostSharp.Aspects.MethodExecutionArgs args)
{
Debug.WriteLine(string.Format("{0} took {1}ms to execute",
new StackTrace().GetFrame(1).GetMethod().Name,
_stopwatch.ElapsedMilliseconds));
base.OnExit(args);
}
}
Each of these aspects will be doing similarly simple work, but in various places throughout the application, the work these guys could do would be valuable. Encapsulating these units of functionality as Aspects allows easy application of their functional contribution later in the development cycle.
Here’s a reminder of the code required to perform the logging and timing when saving a new person to the database. All the visible code is that which was intermingled with the real application code to perform logging and timing in the original codebase.
void WriteToLog(string message)
{
Debug.WriteLine(message);
}
void SaveNewPerson(string firstName, string lastName, string email)
{
new Action<Stopwatch>((watch) =>
{
this.UpdateStatus(string.Empty);
this.WriteToLog("Entering SaveNewPerson");
#region Save to the database
…
#endregion
this.WriteToLog("SaveNewPerson Succeeded");
this.WriteToLog(
string.Format("{0} took {1}ms to execute",
new StackTrace().GetFrame(1).GetMethod().Name,
watch.ElapsedMilliseconds));
}).Invoke(Stopwatch.StartNew());
}
After refactoring this code using the logging and timing Aspects it is much cleaner and, the majority of the code remaining performs a single responsibility – persistence of the data to the database.
[LoggingAspect]
[TimingAspect]
void SaveNewPerson(SavePerson person)
{
this.UpdateStatus(string.Empty);
using (var cn =
new SqlConnection(ConfigurationManager
.ConnectionStrings["testing"].ConnectionString))
{
using (var c = cn.CreateCommand())
{
if (cn.State != ConnectionState.Open) cn.Open();
c.Transaction = cn.BeginTransaction();
try
{
c.CommandText = "insert into person values(@f,@l) select @@identity";
c.Parameters.AddWithValue("@f", firstName);
c.Parameters.AddWithValue("@l", lastName);
var personId = c.ExecuteScalar();
c.CommandText = "insert into emailAddress values(@p,@e)";
c.Parameters.AddWithValue("@p", personId);
c.Parameters.AddWithValue("@e", email);
c.ExecuteNonQuery();
c.Transaction.Commit();
this.UpdateStatus("Success");
}
catch (Exception ex)
{
this.WriteToLog("Exception during person-saving transaction: " + ex.ToString());
c.Transaction.Rollback();
this.results.Text = "Error";
}
}
}
}
Rather than have the functionality mired with code to support the architectural requirements of logging and timing and all that those units of functionality have been applied via attribute-style decoration of the method, thus making the method far easier to read and more concise.
Transactions
Given the database rules of this application’s scenario, transactional processing is needed to make sure the data being saved adheres to the rules and that run-time exceptions are handled by rolling back partial saves. This is another familiar aspect found in virtually any enterprise application that has any level of complexity at the database level. The RunInATransaction Aspect below will provide that ability. Like the previous examples, this class inherits from the OnMethodBoundaryAspect, so that the transaction being used can be handled based on the outcome of the decorated method’s functionality.
[Serializable]
[AspectTypeDependency(
AspectDependencyAction.Order, // this aspect has ordering requirements
AspectDependencyPosition.After, // run after
typeof(LoggingAspect))] // one of these
public class RunInATransaction : OnMethodBoundaryAspect
{
[NonSerialized]
TransactionScope TransactionScope;
PostSharp’s ordering capabilities. In this case, the logging should take place prior to the transaction. When the method begins execution, this Aspect class will intercept and create a new transaction. In essence, this transaction will last the duration of the method’s execution and be managed internally by the Aspect.
public override void OnEntry(PostSharp.Aspects.MethodExecutionArgs args)
{
this.TransactionScope =
new TransactionScope(TransactionScopeOption.RequiresNew);
}
As long as the code within the method executes without any errors the transaction will be committed.
public override void OnSuccess(PostSharp.Aspects.MethodExecutionArgs args)
{
this.TransactionScope.Complete();
}
If at any point during the method’s execution an error should occur, the transaction will automatically be rolled back. The code below rolls back the transaction, undoing all the changes that previously occurred, but will allow execution of the method to occur. Exceptions that occur within the processing will still bubble up to the caller, but the transaction itself will be rolled back and the data integrity maintained.
public override void OnException(PostSharp.Aspects.MethodExecutionArgs args)
{
args.FlowBehavior = PostSharp.Aspects.FlowBehavior.Continue;
Transaction.Current.Rollback();
}
Either way, when the method completes its execution either with success or failure, the transaction is disposed of.
public override void OnExit(PostSharp.Aspects.MethodExecutionArgs args)
{
this.TransactionScope.Dispose();
}
}
With this Aspect as a reusable component of the architecture it can be applied whenever the application logic will require execution within the context of a Transaction. If you’re using an ORM that supports native Transaction support, this attribute will still work. This type of functionality would work precisely the same way, no matter if your database execution is done with native SqlClient functionality or if you’re using NHibernate, Entity Framework, or any other popular ORM that supports DTS.
[RunInATransaction]
[LoggingAspect]
[TimingAspect]
void SaveNewPerson(SavePerson person)
{
this.UpdateStatus(string.Empty);
using (var cn = new SqlConnection(ConfigurationManager.ConnectionStrings["testing"].ConnectionString))
{
using (var c = cn.CreateCommand())
{
if (cn.State != ConnectionState.Open) cn.Open();
c.CommandText = "insert into person values(@f,@l) select @@identity";
c.Parameters.AddWithValue("@f", person.Firstname);
c.Parameters.AddWithValue("@l", person.Lastname);
var personId = c.ExecuteScalar();
c.CommandText = "insert into emailAddress values(@p,@e)";
c.Parameters.AddWithValue("@p", personId);
c.Parameters.AddWithValue("@e", person.Email);
c.ExecuteNonQuery();
this.UpdateStatus("Success");
}
}
}
[LoggingAspect]
void UpdateStatus(string message)
{
this.results.Text = message;
}
The database rules are implemented intrinsically at this point. Not only will the rules be easy to apply in this case, but in all cases that require transactional processing. Through the simple compartmentalization of the aspect of running code within a transaction, the problem has been solved for virtually all situations requiring it.
The highlighted call to UpdateStatus, however, demonstrates a familiar issue during Windows development – the opportunity for exceptions to arise when making changes to GUI elements from external threads. This aspect of application development in a desktop scenario provides another opportunity for AOP to simplify utilitarian code and thereby reducing the complexity throughout the entire GUI layer.
Updating WPF GUI’s from External Threads
This code began with the best of intentions. In both the original and refactored code, the GUI responsiveness was considered. Code from both versions performs the database update in a separate Thread in order to keep the GUI responsive.
private void OnTransactionButtonDemoClicked(object sender, RoutedEventArgs args)
{
var f = this.firstName.Text;
var l = this.lastName.Text;
var e = this.emailAddress.Text;
new Thread(new ThreadStart(() =>
{
this.SaveNewPerson(new SavePerson
{
Firstname = f,
Lastname = l,
Email = e
});
})).Start();
}
Since the SaveNewPerson method is executing outside of the GUI thread, when the GUI update is attempted the Exception arises. Rather than repeat the same code in any situation where the control will need to be updated from an external thread, a new Aspect will be created. This Aspect inherits from MethodInterceptAspect, so rather than affect the method at various times, this Aspect will wrap functionality around the actual method execution. The difference between this and previous Aspects which used the MethodBoundaryAspect base class is that this implementation actually replaces the method invocation it is designed to decorate. In this example, the code will actually wire up the invocation of the decorated methods so that it runs within an anonymous delegate. From a use-case perspective, you’d want to use
[Serializable]
public class UpdateUISafelyAspect : MethodInterceptionAspect
{
public override void OnInvoke(MethodInterceptionArgs args)
{
DispatcherObject o = args.Instance as DispatcherObject;
if (o != null)
o.Dispatcher.Invoke(new Action(() => args.Invoke(args.Arguments)));
}
}
Note how the MethodInterceptionArgs.Invoke method is being called in line 9. That’s a PostSharp way of saying “run the original method functionality here,” and the Arguments property is, of course, the PostSharp way of passing the method parameters into that Invoke call. As you’d have to do repeatedly throughout the code anyway, the Dispatcher call is used to update safely any GUI component from an external thread. Applying this simplified functionality is now as simple as decorating any method that will update the GUI with the UpdateUISafely attribute.
[UpdateUISafelyAspect]
[LoggingAspect]
void UpdateStatus(string message)
{
this.results.Text = message;
}
When the code executes following the attribute decoration, the GUI is safely updated using the common Dispatcher.Invoke methodology. This reduces runtime exception possibilities without creating new code smells by introducing repetitive utilitarian code. If a method updates the GUI and is decorated with this attribute, everything should work just fine.
How PostSharp Works
How PostSharp actually works seems like a huge mystery but really isn’t all that complex from a conceptual level. At compilation time, PostSharp changes the way things work. Don’t panic, but yes, that’s basically it. PostSharp weaves in the code from Aspects created where they need to be applied. A lot of confusion exists around the topic of weaving, so this section will attempt to clarify things somewhat by showing the variation in the compiled MSIL code produced both before and after PostSharp Aspects are applied.
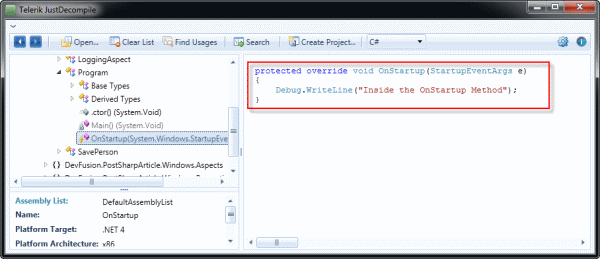
The code for the Program class does a small amount of Debug logging on its own. Looking at this code in a decompiler it is obvious the code isn’t too complex.
Once the logging Aspect is applied to the code’s OnStartup method the output isn’t that much different. Basically, PostSharp calls the functionality specified in the Aspects decorating the method in the expected manner.
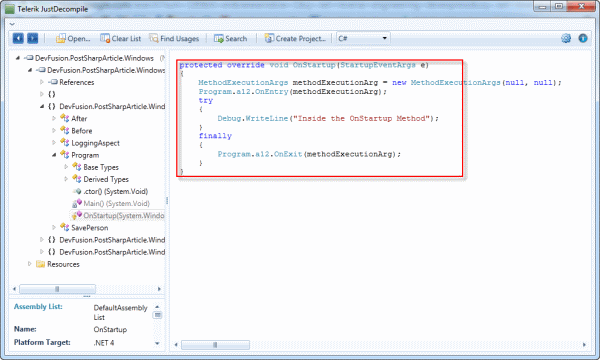
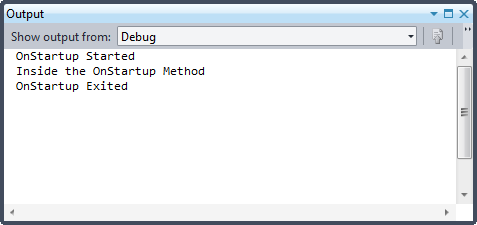
In this case, logging is applied before and after the method’s core functionality executes. When the code is executed, it is obvious the order in which PostSharp is weaving things together. It is an appropriate and expected order and outcome, and demonstrates how the Aspect approach functions at a lower level. The output window below illustrates the execution path following decoration.
NuGet Packaging
PostSharp is available via an easy-to-install NuGet package. You can view more information regarding the use of this package on the SharpCrafters web site. The NuGet command line executable can install the PostSharp package prior to compilation in a build server situation, and all of the options PostSharp offers are available at build time.
The installation of PostSharp (or the NuGet reference/inclusion) will add a PostSharp.targets step to the MSBuild code that compiles any project referencing PostSharp. Since PostSharp does the majority of its work as a post-compilation step, the build process – your compilation from within the Visual Studio IDE, usually – will be automatically modified by this addition.
Summary
PostSharp is one of the more popular means of implementing AOP within the .NET Framework. When applied appropriately, PostSharp Aspects can reduce code clutter and help to maintain architectural standards and practices without overcomplicating the code with intermingled responsibilities. In this example, PostSharp has allowed the refactoring of one application so that:
- Logging code has been extracted into a separate Aspect and removed from the code explicitly
- Performance-analysis code has been extracted into an Aspect and is no longer intermingled
- Transactional processing has been extracted and removed from the code, cleaning up database execution code
- Code requiring the GUI separate-thread invocation has been simplified using an Aspect
Comments