Finding consensus among software developers is hard. But these days it seems, most agree on the importance of the SOLID principles for high inner software quality. Adhering to them promises to lead to more flexible, more evolvable code.
Among these principles, one seems very simple but is hard to get right (as Robert C. Martin puts it). It’s the first principle of SOLID and also one of the oldest principles of software development: the Single Responsibility Principle (SRP).
This article
- starts with a more detailed and more general definition of the Single Responsibility Principle
- continues with a simple approach to spot and contain typical responsibilities of different grain size,
- and finally looks under the surface of the very paradigm used to implement typical aspects to reveal even more responsibilities to separate.
Defining the SRP for Purpose
Wikipedia defines the SRP like this: “[T]he single responsibility principle states that every object should have a single responsibility, and that responsibility should be entirely encapsulated by the class. All its services should be narrowly aligned with that responsibility.”
Unfortunately this is not a very helpful explanation. The Wikipedia author(s) evaded the challenge to define what responsibility actually means. That’s probably why Martin’s definition stuck with many developers: “There should never be more than one reason for a class to change.”
Martin takes up the challenge and equals responsibility with reason to change: “If you can think of more than one motive for changing a class, then that class has more than one responsibility.”
However, Martin’s definition is a bit awkward for practical use because it pertains only to classes. Why should such a fundamental principle only apply to classes of object-oriented languages? What about methods, what about larger “code aggregates” like assemblies or whole applications?
And it’s a bit awkward, because it focuses on code, which is not helpful when there is no code yet. Why shouldn’t the SRP help structuring software before there is platform or paradigm specific code? The SRP could be used like a knife to cut up requirements into responsibilities. Wouldn’t that help software design whether it is done using UML or TDD, whether a developer uses C or Scala?
Here’s a suggestion for a more general definition of the SRP:
A functional unit on a given level of abstraction should only be responsible for a single aspect of a system’s requirements. An aspect of requirements is a trait or property of requirements, which can change independently of other aspects.
This definition is along the lines of Martin’s, but lifts its limitation; it does not focus on classes or even object-orientation, but recognizes responsibilities on many levels; that’s why it uses the general term functional unit instead of class to assign responsibility to. A whole application has a responsibility - a very coarse-grained one - like a small function has a responsibility - a very fine-grained one.
Responsibilities should be non-overlapping at the same level of abstraction. Two methods of the same class (or even different classes) should focus on different aspects. However, two methods in the same class, e.g. a repository, likely will both have to be concerned with the same higher level responsibility, e.g. persistence.
Classes, components, modules, applications should focus on different aspects – but obviously on different levels of granularity. For example an application responsible for ETL (coarse grained aspect) consists of classes responsible for config data handling, CSV file access, database access, or data validation etc. (fine grained aspects).
In addition this definition is less awkward than Martin’s. It clearly binds the SRP to the requirements for a functional unit. To understand if a functional unit adheres to the SRP or not means to understand its requirements. And even if there is no code yet aspects can be identified by analyzing the requirements to guide software design.
Now, applying this more general definition of the SRP surely requires a solid understanding of what aspects of requirements are. For typical aspects this should not be too difficult. But there is more to aspects than a quick glance shows. There are subtle aspects most often overlooked leading to code which is not truly SRP conformant and thus harder to evolve than desirable.
Typical Aspects
The most obvious typical aspects in any software are those concerned with technologies and resources. Let’s take this tiny requirements description as an example:
The program reads in CSV data files and displays them in a page-wise manner. The name of the file to display as well as the number of lines per page is passed in on the command line. Each page is nicely formatted as a table.
Which aspects can be identified from this description? A simple system-environment-dependency diagram helps to spot the coarsest grained aspects (Figure 1).
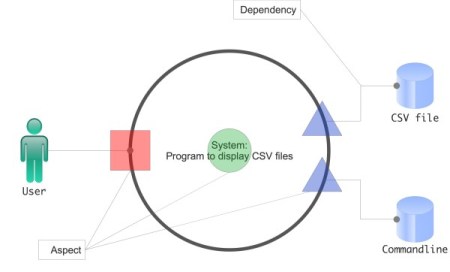
Figure 1
Each interaction of the system with its environment is a different aspect of the system. Interactions take place where the environment accesses the system (left side of Figure 1), and where the environment is dependent on it. Most typically that’s where people are using the system. But interactions also take place where the system accesses the environment, where it’s depending on some kind of resource (right side of Figure 1). Most typically that’s where databases are accessed.
Each such interaction uses some kind of platform API. And each such interaction could change independently at any time.
With regard to the CSV data display program three such environment interaction aspects immediately come to mind:
- A user needs to interact with the program. But this interaction could be through a simple console interface - or it could be through some GUI.
- The program needs to access the CSV data. But the data could reside in files - or it could be sitting in some kind of remote database.
- The program needs to “be configured” with some CSV data source and the page length. But this data could come from the command line – or from a configuration file.
Each interaction can be this way or that way. And all interactions are fundamentally independent of each other, i.e. whether the user manipulates a console UI or a GUI is independent of where the CSV data comes from.
APIs are a sure guide to aspects. Each interaction requires the use of at least one platform API. There are APIs for user interaction, there are APIs for data access, there are APIs for configuration data, there are APIs for system clock access, TCP communication or accelerometer access etc.
According to the SRP usage of such APIs should be encapsulated in different functional units. On this level of abstraction that probably means a component or a class.
In addition to interaction aspects there is one more obvious aspect, though, right in the middle of the system in Figure 1. That’s a “catch all” aspect; an aspect for all non-interaction code. That’s where domain logic falls into.
Every piece of software thus consists of 1+1+n+m aspects which need to manifest themselves in different functional units. There always is at least 1 interaction aspect otherwise there would be no use to the software. There is always some domain logic. There are n additional interaction aspects. And, yes, there are potentially even m more aspects not obvious from a system-environment diagram.
Continuing with the CSV data display program what are traits or properties beyond any interaction API that could change independently?
For one it’s the display format. Maybe the data should not be formatted as a table anymore, where each line contains one record, but rather as “data sheets”, where records are spread across many lines. Formatting the data for display thus seems to be an aspect of its own. It hasn’t to do with the user interaction API or the data source API.
The same is true for the input data format. Maybe the format changes from CSV to fixed fields. This is not a matter of data access, of user interaction, or of display formatting. Dealing with a certain data format is an aspect of its own.
And what about the data size? Is dealing with 1 KB or 10 MB of data the same as dealing with 100 GB? Of course not. 1 KB or even 10 MB of data easily fit into memory. The whole data to be displayed could be read in and then paged through. But obviously this won’t work for 100 GB of data. So changing the size of the data to process is an aspect of its own.
Figure 2 shows the aspects identified so far for the CSV data display program. Each stands for at least one functional unit – e.g. component or class – to take responsibility for it.
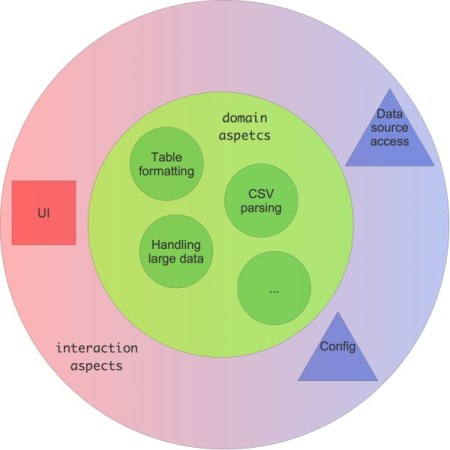
Figure 2
Two things should become clear from this figure:
- Aspects are nested. A coarse grained aspect can be refined into finer grained sub-aspects. There is no limit to the number of levels of aspects.
However, there is a limit to nesting software structural elements like classes or methods. The challenge thus is to map a conceptually arbitrary deep hierarchy to a very shallow hierarchy of artefacts. - There is a mapping between non-functional requirements and aspects. It seems natural to at least view each relevant category of non-functional requirements as an aspect, e.g. performance, scalability, security, and represent them as distinct functional units.
Subtle Aspects
It’s relatively easy to spot functional and non-functional aspects. To then isolate them into single responsibility functional units just takes a bit of discipline, like does refactoring them out if there is already a codebase. This is the foundation for keeping applications, components, and classes clean.
But then what about methods? That’s where the action takes place. Hence it’s even more important to heed the SRP at the method level. Unfortunately, though, this is where most discussions of the SRP end. They do not touch the violations of the SRP intrinsic to the ruling imperative programming paradigm.
What follows is a presentation of aspects often blended together in a single functional unit, mostly methods. These are subtle aspects; their existence will not be equally clear to everyone; their combination is so deeply ingrained in common thinking as well as tools, it’s hard to see them. But at least to flash a brief light on them will greatly help to move code to greater evolvability.
Functional and Non-Functional
It’s very easy to slip into mixing a functional aspect with non-functional ones. The following is close to an example Robert C. Martin gives:
interface IModem
{
public void Dial(String number);
public void Hangup();
public void Send(char c);
public char Recv();
}
This is so common, it almost seems inevitable. On a high level of abstraction the purpose of the interface is to describe a communication aspect. Why not pull together all that’s necessary for communication into a single implementation?
Upon closer inspection, though, it should become clear, communication via a modem hast two sub-aspects to it. Handling the connection and exchanging data can change at a different rate. How to terminate a connection could change separately from how data is sent/received.
Consider this change to the code: making a modem a true resource. Why should switching to a resource interface for connection handling, as often recommended, affect an interface defining some data exchange? Code that formerly looked like this
IModem m = new IsdnModem(); m.Dial(…); m.Send(…); m.Hangup();
should now look like this:
using(IModem m = new IsdnModem())
{
m.Dial(…);
m.Send(…);
}
Now the developer using an IModem implementation cannot forget to free the resource. The C# using statement will take care of this. For this the interface has to be changed like so:
interface IModem : IDisposable
{
public void Dial(String number);
public void Send(char c);
public char Recv();
}
Sure, that’s a very simple change – but nonetheless it affects code, that hasn’t to do with how a connection is handled.
Connection handling is more like an infrastructural aspect of modem communication. It should at least be refactored into its own interface, e.g.
interface IModemConnection : IDisposable
{
public void Dial(String number);
}
interface IModemDataExchange
{
public void Send(char c);
public char Recv();
}
With regard to modem communication handling the connection is a non-functional aspect and sending/receiving data is the functional aspect. The purpose of a functional unit for modem communication is to send/receive data, not to open/close connections. Opening/closing a connection is just a “necessary evil” to be able to send/receive data.
Whether the same class then implements both interfaces, is another consideration. For ease of implementation this could be the way to go. But to be even stricter about the SRP, separate implementations would be better. For that, though, the interface would have to be tweaked a bit more:
interface IModemConnection : IDisposable
{
public IModemDataExchange Dial(String number);
}
interface IModemDataExchange
{
public void Send(char c);
public char Recv();
}
The modem connection implementation becomes a factory for a data exchange implementation. This seems to strike a balance between separating the sub-aspects while making clear they both belong to the same overarching aspect. Also, it’s now obvious that data exchange cannot take place before a connection has been established with Dial().
Another typical case where functional and non-functional aspects are blended together is this:
void StoreCustomer(Customer c)
{
trace.Write("Storing customer…");
using(db.Connect(…))
{
var tx = db.OpenTransaction();
try
{
db.ExecuteSql(…); // Store name and address
db.ExecuteSql(…); // Store contact data
tx.Commit();
}
catch(Exception ex)
{
tx.Rollback();
trace.Write("Failed to store customer");
log.Log("Storing customer failed; exception: {0}", ex);
throw new ApplicationException(…);
}
}
}
This might look a bit artificial, but in fact it’s not. Even though modern O/R mappers might make object persistence easier than this, the basic pattern in this code is typical.
What’s the above code about? How many aspects does it combine?
The obvious responsibility of the code is to store a customer’s data. That much can be gleaned from the name of the method. Unfortunately it’s not easy to spot how this responsibility is fulfilled. It’s buried under a pile of other aspects, non-functional aspects.
This short piece of code is also responsible for connection handling, transaction handling, exception handling, logging, and tracing. Actually storing the customer requires just two calls to db.ExecuteSql().
What makes software hard to maintain is this kind of tying together of aspects. Not only are non-functional aspects spread all over the code base which violates the DRY principle; they also create noise. Reasoning about the purpose of the code becomes ever more difficult.
Of course this is not a new problem. Aspect-Oriented Programming (AOP) has tried to solve it for quite some time. AOP frameworks like AspectJ or PostSharp offer ways to detangle such responsibility overloaded code.
But there are other ways, too. Here’s a suggestion using a continuation:
void StoreCustomer(Customer c)
{
dbServices.WrapInTransaction(
"Store customer",
db => {
db.ExecuteSql(…);
db.ExecuteSql(…);
});
}
The non-functional aspects have been relegated to a method with a distinct infrastructure responsibility – which probably means, the overall persistence aspect consists of at least two sub-aspects to be implemented in different classes: high level domain oriented services, e.g. StoreCustomer() and low level API infrastructure and API oriented services, e.g. WrapInTransaction().
However, solving the problem of responsibility overloading is not just a matter of tools. It’s also a matter of paradigms. This is why the basic form of source code needs to be scrutinized for conformance to the SRP.
Request and Response
How can we assume to solve SRP problems, if we’re not aware of how pervasive they are? Here’s the simplest example of a SRP violation:
var y = f(x);
This code is so basic it’s hard to believe there are two aspects tied together. But there are.
Requesting or sending data is a different “thing” than getting a response or receiving data. How data is sent off can change independently from how data is received.
But isn’t that the same reason? Isn’t it just one “thing” changing: the signature of the function? Yes, it is – but that already is a combination of two aspects, which at least should be uncovered. A function is tying request and response together. Who is given data is also supposed to return a result. And who is sending data is also supposed to receive and process a response.
This might be how the world around us is organized. We call it delegation. A manager asks her secretary for some information on an employee, and an hour later the secretary delivers the information.
But why should the secretary deliver the information? He probably is not the one who compiles it, but rather delegates the task further to some person from HR. Why shouldn’t the HR person inform the manager? This would be much quicker and it would make it easier to get further information, if the manager wasn’t satisfied.
There are many reasons why this type or work organization is so ubiquitous. But why should it be replicated in programming?
It seems so natural to build programs from function calls. But it is this, which leads to hard to maintain source code. The reason is simple: if it’s ok to tie together the request and response aspects, then arbitrary long methods can be created.
There is only so much you can do in code until a method is called. But if this is not the end of the caller’s code, if the caller can continue after the method call by processing the method’s result, then why stop? Why not call another method and another method and another method?
Combining request preparation and response processing thus is the mother of all SRP violation. Because if calling methods has no price tag in terms of dirtiness, then why stop, why not pack together all sorts of method calls?
But if calling a method became costly in terms of code quality, then each method call would be checked. The recurring question then is: What does this call tie together? Does what happens before belong to the same aspect like what happens after? How do both match the caller’s responsibility? Does the called method belong to the same aspect as the caller?
Here are two suggestions using C# to detangle request and response:
void Caller() {
…
f(x, ProcessResult);
}
A continuation can be passed to the method decoupling request preparation from result processing. However, the caller still needs to know who’s responsible for result processing.
Further detangling would require hiding result-processing altogether from the caller. The caller would just fire an event:
void Caller()
{
…
OnF(x);
}
Action<TypeOfX> OnF;
Some other code would take care of binding request handling and result processing together:
OnF = x => f(x, ProcessResult);
Passing a continuation resembles the HR person sending the employee information directly to the manager, bypassing the secretary. And firing an event resembles a manager delegating the whole employee issue instead of dealing with it herself.
Using continuations or events instead of simple function calls might seem clumsy – and it is. Hence the message is not to refrain from simple function calls, but to recognize how they subtly combine two aspects. Functions are a pervasive form of coupling. Therefore they should be used with care. There is a real danger in their ease of use. Deep dependency hierarchies are the ubiquitous result. They are hard to test; they are hard to evolve.
Functionality and Topology
Not only function call hierarchies violate the SRP, also object dependency hierarchies are prone to that. Here’s an example:
class Client : IClient {
IService s;
…
}
interface IService {
S k(T t);
void l();
}
interface IClient {
void f();
}
All seems in order. The Dependency Inversion Principle has been followed. Client and service seem to have distinct responsibilities. What could possibly be the problem with this code?
Beyond Client’s own aspect there exist two additional reasons for the class to change.
If IService or the interface implementation changes, then Client needs to change too. Maybe k() needs to be called with a parameter or l() is split into lSimple() and lAdvanced(). Such changes would naturally ripple through any functional units depending on IService. They pertain to the functional aspect of an interface.
However there is a second reason for Client to change. There is another aspect to the dependency on IService. It’s not just functional; it’s also “topological”.
A method of Client is not just depending on the presence of some method k(), but also on k() belonging to some specific service interface. What, if k() is moved from IService to IProcessor? Client would need to change too, even though k()’s functionality had not changed.
Client thus is depending not only on some service, but also on how “the service landscape is structured”, its topology (Figure 3). The interface IService fences in the two methods Client is using.
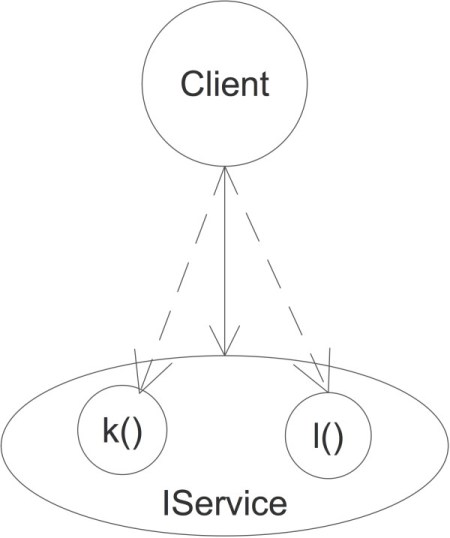
Figure 3
If the topology of the service landscape changes, e.g. further dependencies might be introduced and references need to be changed for using a method.
Applying the Interface Segregation Principle might help to mitigate the problem, but in the end interfaces remain as binders of functionality. Being dependent on service interfaces is the basic problem.
Fortunately removing interfaces from the equation can solve this. Redefining the client like follows has several advantages:
interface IClient {
void f();
Func<T, S> k {get;set;};
Action l {get;set;};
}
Firstly the aspect of topological dependency is removed. Where k() and l() are defined is irrelevant to any IClient implementation (Figure 4).
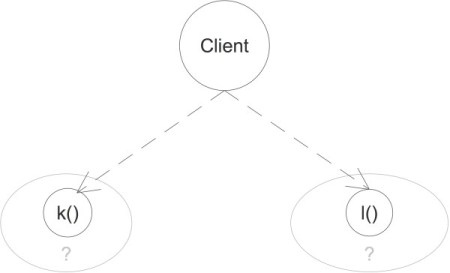
Figure 4
Secondly the specification of a client is now self-contained. All that’s provided and needed is defined in a single interface: IClient. Formerly a developer to implement a client would have to know 1 + n interfaces – the IClient interface plus the interfaces of any service it depends on; now the IClient interface contains all the necessary information.
Syntax and Semantics
Finally maybe the strangest blend of aspects. It’s so pervasive it’s very hard to notice:
void a() {
f();
if (g())
h();
k();
}
Which two aspects got combined in the body of this method, even if all method calls were pertaining to the responsibility of a()? It’s the syntactical aspect, the shape of the control flow, a static view of the code. And it’s the semantic aspect, the dynamic view of the code, its purpose.
Again there are two reasons for the method body to change: one has to do with the semantics of the functions. If for some reason the condition in g() is inverted, the condition in a() needs to be inverted too, from if (g())… to if (!g()) … It’s the method a() which decides at runtime how control actually flows.
But also method a() defines the general shape of the processing. It does that by laying out the functions and methods in a certain way. g() is called after f(), h() is called after g(), finally k() is called. That’s the process definition at design time
Method a() therefore has to be changed if either the process definition is changed or the functionality of one of the process steps is changed. A change in functionality in a lower level of the call hierarchy thus has impact on higher levels. Using a control statement like if effectively spreads aspect logic vertically across a service hierarchy.
To avoid this mixture of aspects, again continuations can help:
void a() {
f();
g(h);
k();
}
The decision if h() has to be called is completely pushed into g(). It not only contains the condition but also the control statement, e.g.
void g(Action doIfConditionHolds) {
if (…)
doIfConditionHolds();
}
This way a() does not need to change if the decision logic changes. a()’s sole responsibility now is to define the basic sequence of operations. This is a design time aspect. The runtime aspect on the other hand has been pushed down the hierarchy into the operations constituting the sequence. Aspect logic no longer is spread vertically.
To strictly separate the syntactic and the semantic aspects all but the lowest level of a call hierarchy should be free of expressions and control statements.
Summary
The Single Responsibility Principle (SRP) is easy to understand and universally applicable - but it’s hard to get right, because aspects are lurking everywhere. Below a layer of typical aspects pertaining to the problem domain and infrastructure there are very fundamental aspects easily interwoven by casual use of imperative or object-oriented languages.
Not only can mixing the obvious aspects of functionality and data lead to hard to maintain code, but also the use of everyday features like method calls and control statements.
This is not to mean one should abstain from using them. Rather it is meant to caution the self-confident developer to slow down a bit and look closer. A code base requires more to be cleaned and stay clean than to spot some ordinary responsibilities and invert some dependencies. To take the SRP seriously means to question some deeply ingrained habits.

Comments