Concurrent applications are applications that perform multiple tasks at the same time and handle the interaction between these tasks. Examples of concurrent applications include rich user interfaces, servers that expose functionality via network, cloud-based applications or trading systems.
As discussed in the previous article, concurrent applications do not have to be parallel. The required throughput can be often obtained just by serializing the requests through a single thread, as long as the primitive operations do not block the thread for a long time (are asynchronous). For example, user-interfaces often use the main GUI thread. Developing applications that perform multiple interacting tasks concurrently is difficult when using the traditional sequential or thread-based architecture. Common issues arising from this approach include low scalability, deadlocks or race conditions.
In the previous article, I introduced F# agents, which can be used to develop efficient and scalable concurrent systems. This article looks at agent-based architecture for concurrent systems from a high-level perspective. It shows how to encapsulate agents into reusable components and how to compose agents to build a concurrent system. In the last part, we’ll also explore several patterns that often appear in concurrent applications that use agents.
Introducing Concurrent Architectures
In contrast with sequential or even parallel systems, the communication patterns of a concurrent system based on agents can be more complicated. You can see the difference in Figure 1. The circles represent objects or agents and arrows represent a method call or a message. A sequential program has a single input and produces single output using just a single control flow. A parallel program is similar, but it may fork and join the control flow. On the other side, agent-based systems may be designed to have multiple inputs and outputs and an agent can be connected to multiple other agents.
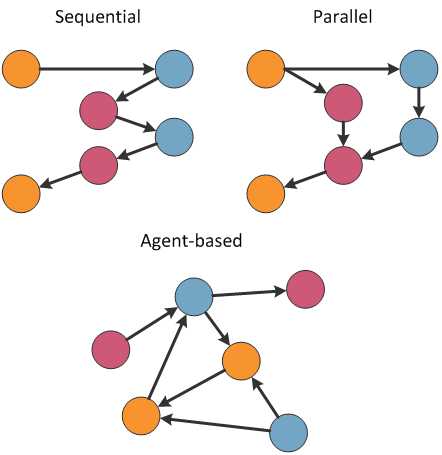
Figure 1. Difference between sequential, parallel and agent-based architectures
As the diagram shows, agents in a concurrent system are often connected with a large number of other agents. If an agent references other agents and send messages to them directly, it would be difficult to understand how the system works, making it difficult to modify and maintain. Instead, agents are usually encapsulated into active objects. The objects are initialized and connected later, either directly or using a configuration file.
Writing Reusable Agents
Rather than showing a complete sample of an encapsulated agent in this article, we’re going to focus on the public interface of a single agent. It’s designed in such a way as to demonstrate how different kinds of communication are represented in F#.
There are two main benefits to encapsulating agents into objects
- It makes the application more readable and more maintainable.
- We can reuse some of the agents across multiple systems.
A concurrent system usually needs agents that implement some application-specific behaviour (such as communication with the stock exchange or a calculation) and agents that implement some general behaviour (such as queuing of work or grouping of items). Agents of the second kind are reusable across a wide range of applications.
Listing 1 shows the public interface of a BlockingQueueAgent type that implements a collection similar to the BlockingCollection in .NET 4. The queue has a certain capacity and when it is full, it blocks callers that try to add more elements. When the queue is empty, it blocks callers that try to get elements from the queue until some elements are added. The key difference between the F# and .NET version is that the agent-based F# solution is asynchronous and so it does not actually block threads while waiting for an element to be available. The interface is an extended version of an agent implemented in “How to: Create Reusable Agents” on MSDN and on the author’s blog.
Listing 1. Public interface of an agent-based blocking queue
type BlockingQueueAgent = /// Creates a queue with a specified capacity new BlockingQueueAgent : int -> BlockingQueueAgent /// Adds element to the queue and asynchronously /// blocks until there is a room in the queue. member AsyncEnqueue : 'TItem -> Async<unit> /// Adds element to the queue without waiting member Enqueue : 'TItem -> unit /// Asynchronously waits until the queue is /// non-empty and then returns an element member AsyncDequeue : unit -> Async<'TItem> /// Triggered when the number of the elements changes member SizeChanged : IObservable<int>
The BlockingQueueAgent type exposes a single constructor and four instance members (F# member definitions read left to right). When created, it takes a number indicating the capacity of the collection. The interface demonstrates the following three kinds of members common to F# agents:
- Asynchronous methods ('TInput -> Async<'TResult>). Probably the most common kind of method is a method that returns an asynchronous workflow like AsyncEnqueue or AsyncDequeue. These methods send some message to the agent and then wait until the agent replies (i.e. when an element becomes available or when it is added to the queue). These methods are typically called from inside an async block in F# or using the Task object from C# to make sure that they do not block a thread while waiting.
- Synchronous methods ('TInput -> unit). Operations that do not have a result and can be completed immediately are exposed as synchronous methods that return unit. In the above example, the Enqueue method just sends a request to the agent, but it does not wait until the element is actually added.
- Notifications (IObservable<'TValue>). Notifications from the agent that are reported when the state of the agent changes or when some operation completes can be exposed as events, represented using the IObservable<'TValue> type that is also used by Reactive Extensions (Rx) Framework. Unlike asynchronous methods, events are not triggered as a reply to some operation and they can be handled by any number of clients.
Reusable agents such as BlockingQueueAgent and application-specific agents encapsulated as objects provide basic building blocks for agent-based concurrent applications. The agents are usually connected in a way that is organized according to some common scheme.
Agent-based Application Patterns
A well-written agent-based application doesn’t typically have an unorganized structure as shown in the diagram in Figure 1. However, the structure is usually more complex than in sequential or parallel programming, because agents are more flexible in how they communicate.
In this section, we look at several common patterns for organizing agents. The patterns can be used as guidelines for organizing agents when writing a certain kind of applications. The list is by no means exhaustive, but it should demonstrate how to think about organizing agents in a concurrent system. A concurrent application can be also composed by using multiple patterns (for different purposes) at the same time.
Worker Agent
The worker agent pattern (Figure 2) is useful when the application needs to run some stateful computations on a shared state. The shared state is protected by the agent and incoming requests that invoke operations on the state are automatically serialized using the built-in buffer that stores messages delivered to the agent. The worker agent can be also safely accessed from multiple threads.
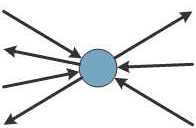
Figure 2. Worker Agents communicate with other agents independently
The worker agent can be used, for example, when an application has a state that is modified using commands from the user-interface, as well as by messages arriving over the network. The user-interface and network components can safely send commands to the agent (without blocking) and the agent updates the state and triggers events that are handled by the user-interface, in order to update the view.
A simple example of the worker agent pattern can be found in the MSDN tutorial that shows how to implement a simple chat server. The application creates an agent that represents a chat room and sends all commands related to the chat room to the agent.
Layered Agents
The layered agents pattern (Figure 3) is useful when we need to perform some pre-processing or checking before calling another agent to do the actual work; for example, to cache results or handle failures. In this pattern, the program communicates with the first layer of agents, which then sends commands to the second layer of agents to do further work (and so on to third / fourth etc. layers as required).
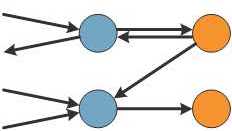
Figure 3. Layered agents pre-process communications from other agents
Using this pattern then, when handling failures:
- The agents from the first layer will send work to the agents in the second layer.
- When a reply is not received in a reasonable time, the agent from the first layer can spawn new agent in the second layer, or it can try forwarding the work to another agent of the second layer.
Similarly, when implementing caching, the agents in the first layer can
- Handle some requests using a cached result
- Call the agents in the second layer to calculate a result if the cache has been invalidated or doesn’t contain the result yet.
Pipeline Processing
The pipeline processing pattern (Figure 4) is useful when you want to process data in multiple steps. The idea behind the pattern is that inputs are sent to the first agent of the pipeline. The first agent does the first step of the processing and sends the result to the second agent in the pipeline, and so on until a final result is calculated.

Figure 4. The Pipeline processing pattern uses multiple agents to calculate a final result
The pipeline processing pattern can be implemented using blocking collections (for example, the BlockingQueueAgent we used as an example earlier) and, as you might expect, by computations that can take a work item from a previous queue of the pipeline, perform the calculation and put the work item to the next queue. In this form, the pattern can be used to parallelize the data-processing, but limit the amount of parallelism to a reasonable level. When running, all steps of the pipeline are executed in parallel, but every step is processing at most one input at a time. A blocking collection then limits the number of items that can be added to the pipeline and it blocks the caller that sends inputs to the pipeline.
The pipeline processing example is perhaps the most complex of the patterns discussed so far, so it is worth looking at a structure of one possible concrete implementation. As usual with patterns, the implementation can have multiple different forms, so this is just one possible approach. I won’t show you a complete source code, but the example should be enough to demonstrate how the pattern works.
The implementation uses the BlockingQueueAgent discussed in the previous section as an intermediate buffer between the steps of the pipeline. The Listing 2 shows a sample pipeline with three steps.
Listing 2. Pipeline processing pattern implemented using agent-based blocking queue
// Initialize blocking queues to keep the intermediate results
let inputs = new BlockingQueueAgent<_>(length)
let step1 = new BlockingQueueAgent<_>(length)
// Individual steps of the pipeline processing
let loadData = async {
while true do
let value = loadInput()
do! inputs.AsyncAdd(value) }
let processData = async {
while true do
let! inp = inputs.AsyncGet()
let! out = processStep1 inp
do! step1.AsyncAdd(out) }
let reportResults = async {
while true do
let! res = step1.AsyncGet()
reportResult res }
// Start all steps of the pipeline
Async.Start(loadData)
Async.Start(processData)
Async.Start(reportResults)
The first step loads data from some input and the last reports the processed data to some output, so there is only a single computational processing step. However, all of the steps may require some time to complete. Both loading and reporting of data may be done using some expensive I/O.
The snippet first initializes two queues that are used to connect the steps.
- The first step is implemented by the loadData workflow. It obtains the input and then asynchronously adds it to the queue. As the queue is a blocking queue, the call may block if the pipeline is still processing all the previously loaded inputs.
- The second step (processData) obtains value from the previous step and then calls processStep1 to perform some asynchronous computation. The result is then stored to the step1 queue.
- The last step (reportResults) then picks the result from the queue and stores it in a file or reports it to the user-interface using the reportResult function.
Pipeline Processing in Practice
The main benefit of the pipeline processing pattern is that it provides a very simple way to balance the tradeoff between overly sequential processing (which may reduce performance) and overly parallel processing (which may have large overhead). The individual steps of the pipeline can run only when the previous step provides input and the next step is ready to accept more inputs. Each step is processing only a single input at a time, so the number of tasks running in parallel is limited by the number of steps in the pipeline.
The example in Listing 2 is based on an agent-based image processing pipeline, which can be found on the author’s blog. In the real-world, the same pattern has been also used in a market analysis system for energy trading at E.ON.
Proxy agent
The proxy agent pattern (Figure 5) is useful when the actual agent that implements the functionality cannot be directly accessed or needs to be protected in some way. The idea of the pattern is that messages are sent to a proxy agent instead of the actual agent. The two agents have the same interface (accept the same type of messages) and the proxy agent just forwards the message to the actual agent, and forwards notifications from the actual agent back to the caller.
This pattern may be useful for example when implementing agent-based communication over the network. This is not supported in the base F# library, but one can easily implement a proxy agent that will serialize messages and transmit them to the actual agent using either TCP sockets or using Windows Communication Foundation. Another possible application is logging all messages that are sent to the agent or detecting some anomalies in the communication. In response to an anomaly, the proxy agent may decide to restart the actual agent.
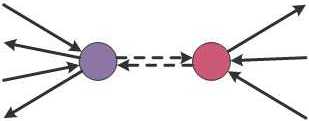
Figure 5. Inter-agent communication in the Proxy agent pattern.
Summary
Concurrent applications typically need to handle multiple inputs or perform multiple tasks at the same time. The typical requirements include certain throughput, the ability to always accept more inputs and fail-safety. Achieving these goals using traditional approach based on explicit threading is difficult and error-prone.
In this article, we looked at composing concurrent systems with thread-safe agents in F#. When combined with immutable messages, this gives an easier way to build concurrent systems without race conditions and deadlocks.
Applications usually consist of several reusable agents (to implement, for example, buffering) and application-specific agents (to implement calculations etc.). These can be implemented in many ways, but they usually communicate with each other in a handful of common distinct ways: in the second half of this article, we looked at four of these very common communication patterns.

Comments