Suppose that in your application, you need to carry out a calculation on a set of tables. The ‘classic’ approach is to create a query that defines the joins between the tables, and selects the data of interest from the joined tables. The hidden problem with this approach is that every time you use the query, the tables have to be rejoined in order to create the result. This can be fairly resource hungry. Instead, you can get around the problem by putting the results into some sort of temporary table, so the values are there whenever you need them.
There are two alternative ways to deal with this requirement in SQL Server – table variables and temporary tables. A temporary table is a table that you create in a special database called tempdb. You create the table, use it, then when you’re finished, drop it from tempdb to destroy it. Table variables are a bit like temporary tables, but they work mainly in memory; as the name suggests, so you’re essentially creating a variable that has the structure of a table. Temporary tables have been around for longer so are probably better known than table variables, but both have their advantages and disadvantages.
Temporary tables and table variables give you more or less the same basic facilities. While a table variable might sound like it’s a purely memory-based variable, in fact, like temporary tables, some aspects of table variables are written to the tempdb database.
So long as you have enough memory, both table variables and temporary tables are mainly kept in the memory data cache. Both will also write to disk if your result sets become too large. This is something that isn’t well enough known, but you can see the effect quite clearly if you create a table variable then load a large table into it – your tempdb will suddenly expand as the data gets too great for the data cache. However, temporary tables have their structure stored in the tempdb database, and they have the overhead of extra indexes and statistics, so tend to end up writing to disk more frequently than table variables.
One reason why many developers prefer to use table variables is the fact that if you use a temporary table in a stored procedure, then a separate copy of the temporary table will be created for each user in your system who makes use of that stored procedure. So if you know your application requires around 5MB of space for the temporary tables, and you know you’re going to have 100 users, you’ll need 500MB of space in tempdb. You can get around this problem by writing your application to make use of global temporary tables, in which case all the users share the same table, but then you need to write your code to take account of this. If you’re working with ‘normal’ temporary tables, SQL Server identifies the different temporary tables by internally adding a numerical suffix to the name.
As a rule of thumb, if your result set is going to be small enough to be kept in the data cache (maybe a few multiples of 8KB database pages), table variables will give you the best performance; if your result set will be larger, you might find temporary tables are better, as they have indexes and statistics. The disadvantage of temporary tables comes in building these extras in the first place.
You can create table variables multiple times as they have local scope, but temporary tables persist until you drop them
One of the main differences between temporary tables and table variables is the fact that a table variable acts like a local variable. Its scope is limited to the function, stored procedure, or batch it is declared in. Within that scope, you can use it just as you would any other table. One advantage of table variables over temporary tables is that table variables are automatically cleaned up for you at the end of the function, stored procedure, or batch in which they are defined, whereas you have to clean up temporary tables for yourself by remembering to drop them from the tempdb database. Looked at from the other viewpoint, though, you can get rid of a temporary table any time you want by destroying it explicitly using a DROP statement, but the table variable remains in existence and you can’t get rid of it until it goes out of scope.
If you’re working with a stored procedure, table variables have the advantage that they cause fewer recompilations of the procedure than would be the case if you’d used a temporary table. If you use temporary tables in a stored procedure, they can cause it to be recompiled every time it is executed. If the temporary tables referred to in a stored procedure are created outside the procedure, that will cause recompilation. You will also see recompilation if you have DECLARE CURSOR statements whose SELECT statements reference a temporary table, or if you have DROP TABLE statements before other statements referencing a temporary table. In each of these cases, changing to a table variable rather than a temporary table will avoid the repeated recompilation.
Table variables need fewer resources for locking and logging, partially because any transactions involving them last only for the duration of an update on the variable. A final advantage is that the performance of your procedures may improve with table variables, though whether this is the case or not can’t easily be forecast.
However, table variables aren’t always the best solution. You can’t create non-clustered indexes on them (though PRIMARY and UNIQUE constraints will create system indexes). The inability to have a non-clustered index means some queries can run slower than they would if you had a temporary table.
You also lose the statistics that would otherwise be collected. This might not seem a big problem, but you need to remember that the query optimiser makes use of the statistics to work out the best optimisation plan, so that you may again end up with a slower query than you would otherwise have expected.
The temporary table exists in tempdb; the table variable doesn’t
One side effect of the local scope of table variables is that you can’t use them as input or output parameters, so you can’t (for example) pass them to another stored procedure as input. If you find yourself wanting to do this, you need to use a temporary table. You also lack the ability with table variables to copy one to another, unlike with a temporary table.
Another point to note is that table variables take no notice of transaction rollback. So, for example, if you declare a table variable, then insert some data into the table in a transaction, it stays in the table, even if the transaction is then rolled back. This can cause confusion, but so long as you’re aware of the rules, you can take account of them.
There are also some limitations on the type of statements in your queries – you can’t use SELECT INTO, for example, or INSERT EXEC. In fact, the whole way you use the EXEC statement (and the sp_executesql stored procedure) needs rethinking if you want to use table variables in your dynamic SQL. Table variables can only be referenced in their local scope. This means that if you create the table variable outside the EXEC statement or the sp_executesql stored procedure, you can’t run a dynamic SQL Server query that refers the table variable. You can get around this by creating the table variable and performing all the processing inside the EXEC statement or the sp_executesql stored procedure.
So which should you choose and when? The advice from Microsoft is that you should use table variables as the preferred solution. However, if you’re going to have more data than can comfortably be kept in the data caches, or if you’re going to re-use the table repeatedly, you should consider changing to a temporary table, as you then have the option of creating indexes to improve the performance of your queries. However, essentially, it’s a case of suck it and see – you can only really work out which method is better by trying each one in turn and seeing which version makes your application run faster.
So how do you use table variables?
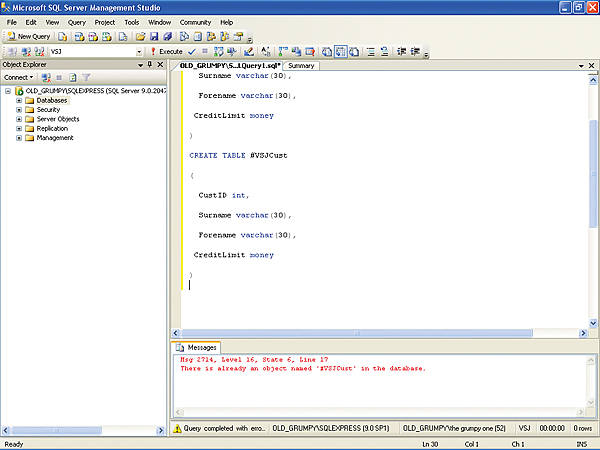
You declare a table variable in T-SQL in a similar way to the way you create a table. For example, suppose we wanted to create a table variable called VSJCust:DECLARE @VSJCust TABLE ( CustID int, Surname varchar(30), Forename varchar(30), CreditLimit money )This is very similar to the syntax for a temporary table, where you’d say:
CREATE TABLE #VSJCust ( CustID int, Surname varchar(30), Forename varchar(30), CreditLimit money )This similarity can be useful – it means minimal changes to test whether the temporary tables version or the table variables version performs better in your case.
You can see the effects of choosing between the different options by running the code above using the Query Analyzer in SQL Server to run the commands on one of your own databases. If you create both the table variable and the temporary table, then run the following code:
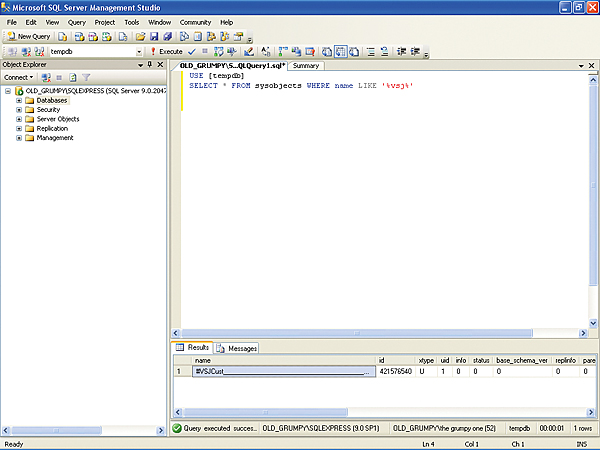
USE [tempdb] SELECT * FROM sysobjects WHERE name LIKE ‘%vsj%’You’ll see that there is only one record from the tempdb database returned as a match (unless your database has other tables with VSJ in the name). So the table variable has no internal representation in sysobjects, and the temporary table does.
It’s also worth seeing the differences in terms of scope. If you were to try re-running both the DECLARE command on the table variable, and the CREATE command on the temporary table, you’d be allowed to re-declare the table variable, but would get an error message if you tried re-creating the temporary table telling you that there was already an object called #VSJCust in the database.
Keys, Identities, and default values
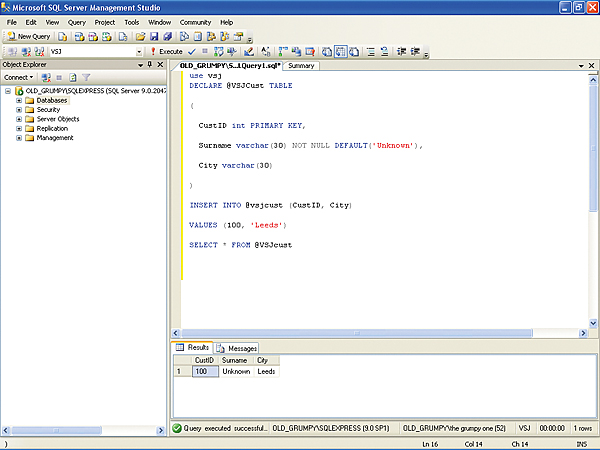
Going back to table variables, when you’re declaring your table, you can define primary keys, identity columns, and default values:DECLARE @VSJCust TABLE ( CustID int PRIMARY KEY, Surname varchar(30) NOT NULL DEFAULT(‘Unknown’), City varchar(30) )…or:
DECLARE @VSJCust TABLE ( CustID int IDENTITY(1,1) PRIMARY KEY )If you’re not familiar with Identities, they’re the way SQL Server creates an auto-incrementing value. The Identity element has two arguments. The first value is the value assigned to the first row added to the table, and the second value is the increment. The default is (1,1), so you could in fact have written the line above as:
CustID int IDENTITY PRIMARY KEY,You can also use the normal SQL Server Constraint to specify any limits on the data that is valid:
DECLARE @VSJCust TABLE ( CustID int, Surname varchar(30), Forename varchar(30), CreditLimit money CHECK(CreditLimit < 50000.0) )This would ensure the credit limit was lower than £50,000.
Having created the variable, you could then select some data from your database customer table to populate the table variable:
INSERT INTO @VSJCust (CustID, Surname, Forename, CreditLimit) SELECT CustomerID, CustSurname, CustForename, Credit) FROM [Customers] WHERE Customer.City=’Leeds’You aren’t just limited to selecting data; you can update and delete records in the table variables:
UPDATE @VSJCust SET CreditLimit = CreditLimit * 3 WHERE CustID = 100 DELETE FROM @VSJCust WHERE CustID = 50
Tips and tricks
As I mentioned earlier, there are some restrictions to what you can do with a table variable – no non-clustered indexes, for example. The way you use dynamic SQL also needs to change. Suppose you had a ‘normal’ table called VSJCust. In dynamic SQL, you could use it in an EXEC statement along the lines of:EXEC sp_executesql N’SELECT * FROM VSJCust’(The N before the string tells SQL Server to treat the constant string as an nvarchar data type.) However, if you tried the equivalent of the above with our @VSJCust table variable:
EXEC sp_executesql N’SELECT * FROM @VSJCust’…then you’d get a error message telling you that you “Must declare the variable ‘@VSJCust’”. Of course, it’s easy to see (and rectify) the problem if you’ve entered the dynamic SQL as a real static string as shown above. Database programmers tend to use dynamic SQL to let the user make some selections, then build the dynamic SQL string on the fly when the application is actually running, and the error is much harder to spot in this case.
So if you’re letting the user make choices, then building your EXEC strings on the basis of those choices, the advice is to steer clear of table variables – use temporary tables instead. It is true that you can declare the table variable inside the dynamic table, but the nagging doubt that you’ve somehow referenced a table variable and the error won’t show till months later is just too high a price to pay.
Using default values in table variables
In some places where you want to use a table variable, you can get around the limitations by using an alias. For example, if you want to use the table in a join, you’d normally get an error message. However, if you set up an alias, the join will work fine:
SELECT Surname, City FROM Customers INNER JOIN @VSJCust VC ON Customers.CustID = VC.CustIDAnother area where you simply need to remember what the rules are is that of transaction rollback. In general, if you have a normal table called VSJCust and code along the lines of:
BEGIN TRANSACTION INSERT INTO VSJCust (CustID, Surname) SELECT CustomerID, Surname FROM [Customers]Then if later on you have:
ROLLBACK TRANSACTIONThe result will be that the table VSJCust will be returned to its original state and the number of rows will be exactly what it was when you started. If, on the other hand, you’re working with a table variable, any rows selected and inserted will stay inserted. So don’t rely on transaction rollback to cancel actions on table variables, because it doesn’t work.
So which should you use?
So how can you decide when to use a temporary table and when to use a table variable? And when should you choose a global temporary table?The rule is pretty much, choose a table variable as the default. Then re-assess the situation in the following circumstances:
- If you want to use transaction rollback
- If you want to pass the resultsets of your tables from one stored procedure to another
- If you want the query optimizer to be able to work out how best to run a complex query
- If you’re getting really clever with dynamic SQL, you need a temporary table.
Kay Ewbank, Editor of Server Management magazine, is an experienced database analyst who has followed the development of database technology from dbase through to SQL Server.
Comments