So databases work in terms of tables while data values are closer to being objects. We arrived at this situation because databases developed back in the days of punched cards and mainframe computers as the data element of Cobol programs, but were we to start again, chances are we wouldn’t go down that route; we’d start with the idea of objects and how to manipulate them. There are object databases out there, but the problem with most of them is that they ignore all the hard work that has gone into making relational databases as good as they could be.
Now consider the other half of the equation; the language you develop in. Most modern languages expect you to be working with objects, and any real-world application is probably going to expect the data to be persisted and that you will be able to retrieve it as and when necessary. This brings us back to the database. If the back end is a relational database, then the rich objects you’ve been working with will need to be flattened and stored in tables. This takes a lot of work, and any changes you make to the objects as they are created has to be re-mapped manually onto the underlying database structure. According to some estimates, this can occupy as much as 40% of the development time in an application.
So what’s needed is a database that understands both objects and relational structures, and a way of working with that database from standard programming languages without spending forever re-mapping your objects when you make changes during the development.
The combination of InterSystems Caché database and Jalapeño Persistence Library for Java is one possible solution.
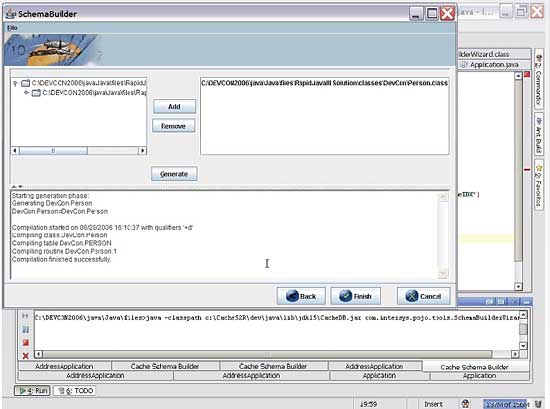
Jalapeño comes with a schema builder that you run from within your Java development environment
Object-relational mapping
Caché is a multidimensional database that can be used with both relational and object data. It is described as a post-relational database, and behind the scenes stores its data in sparse multidimensional arrays. The advantage this offers is that the multidimensional nature means the underlying structure is sophisticated enough to be able to represent an object, no matter how complex, while still allowing a two-dimensional tabular view for relational data. Caché is a SQL compliant database so you can make use of SQL queries to find out about your data, and from the other side, Caché supports encapsulation, multiple inheritance, polymorphism, embedded objects, references, collections, relationships, and BLOBs, so you can carry out all ‘normal’ work on objects.Jalapeño is short for JAva LAnguage PErsistence with NO mapping, and it takes care of the object-relational mapping so you can program in Java without worrying about how you’re going to have persistent objects, or how those objects are going to be stored within the database. This way of working means you don’t have to be a Caché expert; so long as you’re familiar with Java, you can work out what you want to do in Java terms, and let Jalapeño do the rest. You develop your data classes and build your applications using whatever Java development environment you prefer, and leave Jalapeño to take care of how your data objects will be stored. Jalapeño then derives persistent Caché classes from your Java data class definitions. Because your data is stored in Caché, you can then query it using SQL via JDBC.
What happens with Jalapeño is that it takes Plain Old Java Objects (POJOs) that have been developed for an application and runs them through a process that uses Java introspection to find out what’s in them. From that information, Jalapeño automatically creates an object database schema. If you make any changes to the object model, Jalapeño changes the object database schema for you so you don’t waste time remapping to the database. Because basic Java doesn’t have knowledge of database objects and the type of action you’re likely to want to carry out, Jalapeño makes use of Java 1.5 annotations. It comes with a set of annotations that handle the database interactions, for example, you get an annotation that lets you look up a record on a particular index, and other annotations deal with aspects such as relationships, uniqueness, and referential integrity.
Jalapeño consists of two main components – a Schema Builder, and an Object Manager. Both are Java classes provided as part of the CacheDB.JAR file.
The Jalapeño SchemaBuilder is used to generate Caché classes from your Java source files. You can run SchemaBuilder either from the command line or from the SchemaBuilder Wizard, which is a GUI interface that automates the process of creating a SchemaBuilder properties file.
Whichever method you choose, the SchemaBuilder will then automatically create and compile Caché classes that correspond to those Java classes in which you need persistence. You use the library of annotations in your Java class definitions to tell the Schema Builder details such as the fact that an index is needed here, or a relationship with another class there, or a constraint in that particular property value.
Persistence
To get over the problem of Java classes not being persistent, you use the Jalapeño Object Manager. This is a Java class that, when instantiated in a Java application, handles the interactions between the application and the underlying persistent data that is stored in Caché. The type of thing the Object Manager deals with includes storing objects in the database, retrieving existing objects, setting values in object properties – all the interactions between your application and the database. Because Caché lets you use both object and relational methods to access the data in the same database connection, the Object Manager is also responsible for dealing with any SQL queries you want to put to the database.One reason why relational databases continue being so popular is because developers know they’re the safe option – you know before you start what the limitations are, you know there are more or less equivalent alternatives if your chosen product gets dropped or takes some other wrong turn. If you like the sound of Caché/Jalapeño, but worry about a way out if it’s not the solution you thought it was, it’s worth knowing that Jalapeño does offer database independence. There’s an export utility that will convert the Caché class schema that has been derived from your Java class definitions into a DDL file that can be imported into a relational database.
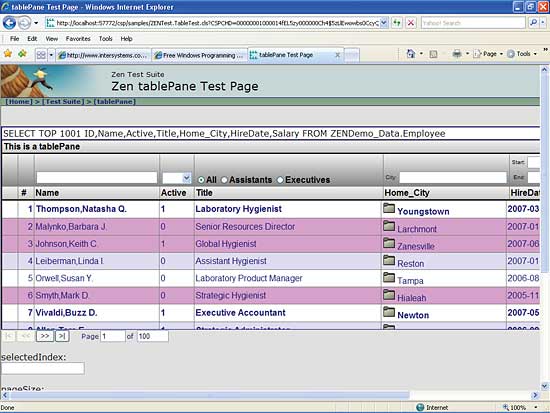
You can create data-backed web pages using grids and other data-aware controls using Zen
To set up persistence with Caché and Jalapeño, you simply create a Namespace and an empty database using the Caché System Management Portal. You then run the Jalapeño SchemaBuilder to create the Object Storage in the database. This sets up a one-to-one relationship between your POJOs and the Caché Object Classes that are defined in the database. You’ll probably need to add annotations for database features such as relationships and indices.
You interact with your objects using ObjectManager. This is a Java class that provides methods to access and manipulate Caché database objects from within your Java application. For example, here’ the code to create an Employee object and set its properties:
Employee newEmp = new Employee (); newEmp.name = “Fred Bloggs”; newEmp.department = “sales”; newEmp.salary = “30000”;This object hasn’t yet been added to the persistent database, so the next step is to use the insert() method to save it in the database:
objManager.insert(newEmp, true);After the call to insert(), the object is open and attached to the database, so a call to getId() would return a valid value:
myId = objManager.getId(newEmp);You could then destroy the object (or more likely move on to a different employee record:
newEmp = null;…and later use the saved Id to retrieve the first object from the database:
newEmp = (Employee )objManager.openById( Employee.class, myId);This returns an iterator that you can use to traverse the objects that are returned. In addition to using a method as shown above, you can use JDBC and ‘normal’ SQL. This can be used to run more complex SQL queries based on SQL Joins and Views. So long as the query results include the Object ID, you can then access the results as objects, and move from object to object along the object tree – to go from an order record to the customer who placed the order, for example.
If you want to add database specific features such as indices and relationships, you do so using annotations. For example, the following code adds an index and a relationship:
package tinyPkg;
import com.Jalapeño.annotations.*;
@Index (name=”EmpIdx”,
propertyNames={“ssn”},
isPrimaryKey=true)
public class Employee {
public String name = null;
public String ssn = null;
public int salary = 0;
@Relationship(
type=RelationshipType.MANY_TO_ONE,
inverseClass=”Department”,
inverseProperty=”staff”)
public Department department = null;
public String showProps ()
throws Exception {
return “ name:” + name +
“ ssn:” + ssn + “ salary:”
+ salary;
}
}
Caché plus Zen
If you’re attracted by the prospect of Jalapeño, you need to know about the rest of Caché. We’ve looked at Caché before in VSJ, but a new version (Caché 2007) has been launched more recently, with the addition not only of Jalapeño, but a new web browser development feature called Zen.As mentioned earlier, Caché provides a multidimensional database that can be used with both relational and object data, along with the tools and utilities necessary to create database applications that use the database, and administrative tools to work in a more traditional database administrator manner.
As developers, you’re going to be more interested in the way you develop your databases. If your experience is more on the database front than on the Java front, you can develop entire applications within Caché itself. The design environment is called the Caché Studio, and this takes you through all the tasks of developing a database application and the objects within it; all you have to do is to answer the questions asked by the set of wizards. The Studio lets you create class definitions, Caché Server Pages, and routines. It includes an editor that has syntax checking and code colouring, graphical debugging, and a point-and-click class inspector.
If you choose to work within Caché, you can choose between Caché ObjectScript and Caché Basic. ObjectScript is the original Caché scripting language, and offers the ability to work with your data in whatever way is most appropriate – as objects, as relational tables (using SQL), or as multidimensional arrays.
While Jalapeño makes developing in Java an attractive proposition, you can choose to expose your Caché classes to other languages including Java, C++, Perl, Python, .net, and XML.
If you’re working on a web application, you have two tools at your disposal. The first is the Caché Server Pages (CSP) technology, and this is both an architecture and toolset that you can use to build an interactive CSP application. Using CSP, you can dynamically generate Web pages based on data from a Caché database. CSP provides session management, page authentication, and the ability to perform interactive database operations from a Web page.
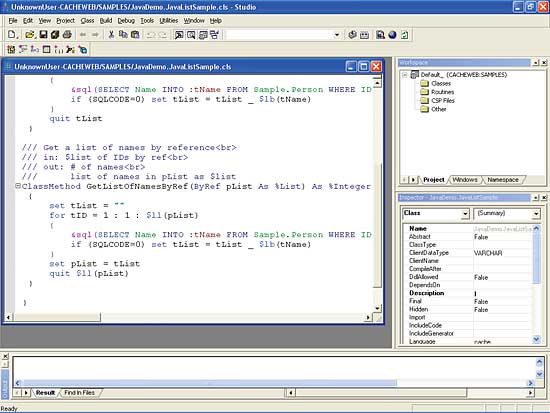
Caché has a good development environment of its own, the Caché Studio
The second tool for Web development is Zen. This is new in Caché 2007, and is complementary to CSP. Zen is an implementation of AJAX Asynchronous JavaScript and XML), and it offers a set of pre-built components within Caché that you can both use as is and extend as necessary. The components automatically create standard HTML and JavaScript, and because Zen uses a standard HTML client, you don’t need any additional client components. Zen comes with a large library of pre-built components that you can use to display your data, including data-aware combo boxes, tables, grids, tabs, tree controls, menus, and grouping components. Using Zen, you can define forms based on the controls, and your applications can then load data into the forms; validating the contents of forms; and save the form contents back to your database.
Zen makes use of a “shared object” data model that shares data between the server and the browser as objects so avoiding the need to parse XML. It’s multi-lingual so you can build a page in one language, then let Zen extract the text in that original language. This is replaced by a code, which is stored along with the text in a database. The text can be given to a translator to be converted into other languages, and to create a local language version of your pages, you simply retrieve the appropriate text based on the language code at run time.
Conclusion
Caché has been a strong alternative to standard relational databases for the past few versions, and those developers who’ve tried it find it offers many advantages over non-object databases. The addition of Zen and Jalapeño in the current release increases its attractiveness, and should spread the message further. Caché 2007 is available on Windows, Linux, Mac, UNIX and OpenVMS.Kay Ewbank, the editor of Server Management magazine, is an experienced database analyst who has followed the development of database technology from dbase through to today’s modern relational and post relational databases.
Comments