Transact-SQL is a query language used for data-centric applications. The power of the SQL language has been improved over the years by making changes to the ANSI-SQL standard, giving us more built-in functions. In addition, Microsoft has added a lot of functionality to the SQL standard by providing very specific T-SQL additions that are not part of the ANSI standard.
SQL Server 2005 has incorporated a lot of enhancements and improvements to the language statements. These changes are implemented to better adhere to the ANSI standard, but also a lot of functionality was added based on customer needs and feedback.
In this article I will highlight some of these enhancements and give you the opportunity to test some samples in SQL Server 2005. I will provide examples based on the new AdventureWorks database, the sample database provided with SQL Server 2005, which replaces the Northwind database. Personally, I am very excited about this new sample database. It provides you with a good overview of new SQL Server 2005 features, and also has some nicely filled sample tables that you could consider using to fill your own test environments. Of course, it also integrates features such as SQL Service Broker, XML datatypes and even data partitioning.
I will focus primarily on the following T-SQL improvements:
- Ranking and Windowing functions
- Aggregation with PIVOT/UNPIVOT
- OUTPUT operator
Ranking and Windowing functions
In previous editions of SQL Server, it was difficult to provide row numbers within a resultset. One of the things you could do to simply generate a row number in front of your columns was first insert it or join it with a temporary table. SQL Server 2005 has implemented different methods to provide us with ranking and row numbers. Let me describe these features and provide you with some samples.ROW_NUMBER()
Row_Number() is the most basic function within the new SQL Server 2005 ranking functions. It generates a column that returns the row’s number within the result set.
Base syntax:
ROW_NUMBER ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )RANK()
RANK works almost the same as a ROW_NUMBER() except that it does not break ties, and gets the same values generated for non-unique values. Also, because duplicate values within the RANKing order are considered to have an equal match, they will get the same RANK value. The next non-matching row however is ranked with the row number as returned in the result set, and therefore skips numbers in the tie.
Base syntax:
RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )DENSE_RANK()
DENSE_RANK works exactly like RANK() except for the fact that DENSE_RANK will not skip numbering within the tie. The T-SQL Statement further below shows the implementation and also the difference between the various Ranking functions.
Base syntax:
DENSE_RANK( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )NTILE(x)
Another ranking function added is NTILE(x). NTILE will evenly divide the resultset into approximate pieces and assign each piece the same resultset.
If I have a table that contains 100 records, and I use NTILE (50), it will break and divide into 50 pieces and assign the records specified in the order by clause of the NTILE function.
Base syntax:
NTILE (x) OVER ( [ < partition_by_clause > ] < order_by_clause > )The transact-SQL Statement in Figure 1 shows us a perfect combination and comparison of the new ranking functions, including their differences.
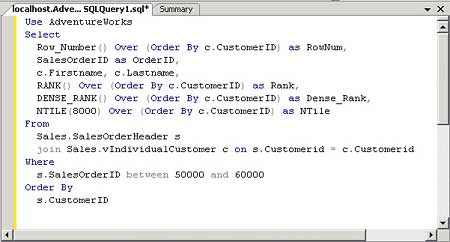
Figure 1
This returns the resultset shown in Figure 2.
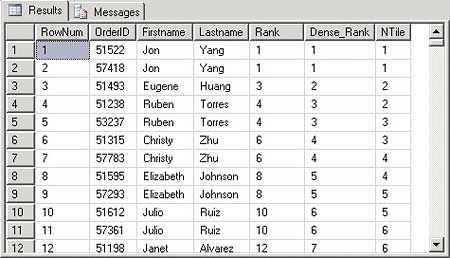
Figure 2
PARTITION BY
Another concept of Ranking is Windowing. This is sometimes also referred to as partitioning, however partitioning might be a confusing term, since one of the new features in SQL Server 2005 supports the partitioning of tables and indexes. Windowing in SQL Server 2005 is implemented by using PARTITION BY in the ranking function.
The PARTITION BY statement divides the result set into equal partitions or subsets. This could be considered as a GROUPING clause on a ranking function in order to achieve a separate ranking for each partition or window within the PARTITION BY statement.
The example in Figures 3 and 4 uses ROW_NUMBER in combination with a PARTITION BY to assign a row number per order, grouped per customer. The GROUP BY customer is achieved by implementing the PARTITION BY.
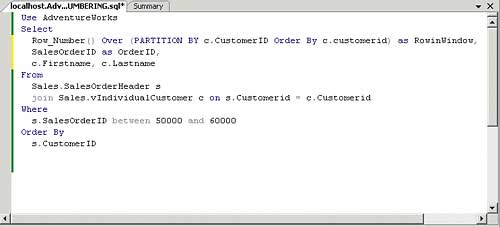
Figure 3
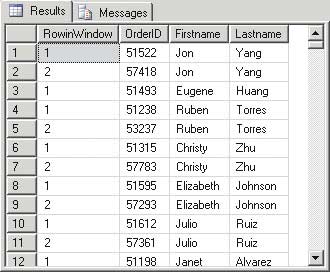
Figure 4
You can of course use the PARTITION BY statement with all of the new Ranking functions.
The PARTITION BY statement is always used in conjunction with the OVER keyword.
PIVOT/UNPIVOT
Very often within databases your data is stored in such a way that you want to rotate rows into columns or do the reverse. This is easy to perform within an Excel spreadsheet, but complex within the T-SQL language in earlier versions of SQL Server. Pivoting provides you with an excellent way of re-shaping and re-organising your data, and is one of the key features of Business Intelligence, when the technique is often used to populate data warehouses.
Let’s have a look what we can do with the PIVOT function. A useful feature of the PIVOT function is the range of benefits to make statements easier, instead of having to write complex CASE statements.
In the example shown in Figures 5 and 6, we create a table that has a customer name, the product that the customer has bought and the price paid for that product.
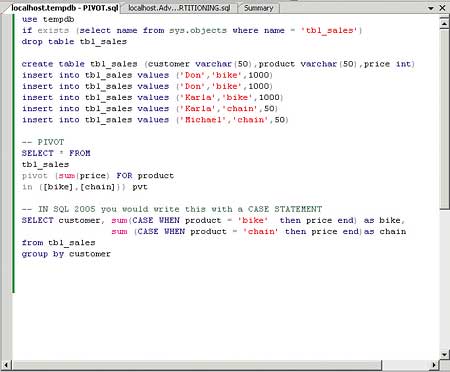
Figure 5
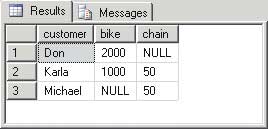
Figure 6
We want to summarise the total amount a customer spent on a certain product. In order to do that, you have to use PIVOTING, or a more difficult to use CASE statement with SQL Server 2000. The resultset however will be the same, as you can see in this comparison with the ‘OLD’ syntax.
It will probably come as no surprise to learn that UNPIVOT performs the reverse operation of PIVOT, by rotating columns into rows. One thing I don’t like about the PIVOT function is that it doesn’t support the use of INNER select in the IN clause of the PIVOT feature. So within the IN clause I would need to be able to provide the ‘DISTINCT’ values of the columns I want to pivot. You should consider using dynamic SQL in order to generate the IN clause.
Working with OUTPUT
Very often we want to see or retrieve within a SQL Batch what the actual insert values were on default columns, or we want to have functionality that shows us the old value of an update as well as the new value. With SQL Server 2000 we use triggers in order to achieve this, and use the inserted and deleted tables within the trigger.Sometimes you want this functionality without having the overload of creating a trigger on a table, because it would be nice to have this feature just available with one specific statement. One of the new features I really like here is the OUTPUT clause that can be used with a DML statement. You can use the OUTPUT as an option into a statement to insert the result into a table defined datatype.
In the example shown in Figures 7 and 8, I will show you the ‘old’ value and the new value that will be outputted after completing the update statement.
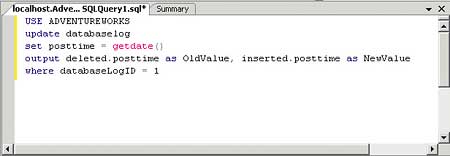
Figure 7
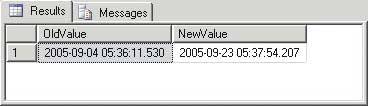
Figure 8
Very interesting to know as well is that the ‘databaselog’ table I use in the example is used by one of the other new features with SQL Server 2005, using DDL triggers and Event Notifications.
Conclusion
The ranking functions provide some rich new functionality. While PIVOTING does not provide everything that I expected from its implementation, I can still benefit from its usage since it can save me a lot of work in implementing simple PIVOT functionality.The OUTPUT clause is something I really like – you can use it in a situation where you want the functionality that you would normally put within a trigger – by inserting the OUTPUT values into a table datatype.
This article has only covered some of the enhancements to T-SQL in SQL Server 2005, and there are many more interesting areas to be reviewed.
Dandy Weyn is Consultant Technologist SQL with QA. He has presented at conferences and Microsoft ISV Events in the US. Being a Microsoft Certified Trainer he teaches courses on SQL all over the world, and is part of QA’s courseware development team on SQL Server 2005.
Comments