One of the best things I like about developing software, is that every project is never like the previous one you’ve built.
That’s right. But underneath all these systems, lies a set of common architectural modules, that every system should have. If you are an architect with a team of developers, or one developer with a team of managers, here’s a list of a set of modules, frameworks and strategies you should have in mind. Not all of them would necessarily apply to you, but if I were you, I would at least think about each one. So if you are starting a new project – lucky you – from scratch, or coming to an old project with a mandate for change, here’s a small checklist.
ORM Framework
Many programmers would start their efforts with writing a Data Access Layer. But nowadays, it is becoming increasingly clear that not only it is important to have a DAL, but a layer with objects (that is, classes) that maps to database entities. This is ORM.
A good ORM layer would have 3 minimal features:
- It should allow automatic creation of objects. This is a nice example of the DRY principle. All the database-related fields are defined in one place: the database. With one click of a button – running a script – the classes are automatically created. This is code you don’t touch. When you change one field in one table, you run this script again, recreating the whole body of classes once again.
- It should support record CRUD – creation of a new record, updating of an existing record, and deleting of a record – all as operations availabe on the classes created.
- It should know to deal with relations between tables. For example, if you insert a new order, you usually need to insert the order header table, with the master order details, and then a list of recorders int the child order details table. Traditionally, you would insert a new record in the master table, and then take the key that was created and use it as a foreign key for the child records. A good ORM would abstract that for you. For example, in Propel you would write:
... $order->addOrderdetails($orderdetails); $order->save();…and this last save() will insert the whole tree – even more than just one level deep, by the way
Tiered Framework
Once there was the 3-tier application, divided into the user interface (UI) layer, business logic layer, and database layer. The ORM is obvoiusly the database layer. Now the question is, what on earth is business logic? I always find this term a bit vague. When you build an application, what is not business? I think that the answer is, if it’s UI, then it’s not buisness logic. To add to that, business logic usually includes back-office processes such as automatic emails, pricing calculations, conversions, and more than all – decisions. For example, what form to present next.What would such a separation give you? In web sites, this tiering would allow you to change the UI easily without changing the underlying, um, business logic. If you are talking about a desktop C++ application, then the benefits could include – how exciting – a cross platform for Mac. wow!
How to do it? in general I would leave it to you and your framework. I could say, though, that in my web sites the mechanisms I’ve created simply put all the UI related code in certain folders and classes, from which the forms and html have been built. In other applications I’ve used a tree-like module structure, where modules are interconnected by subscribing to events (more on that later) that each module can publish. The UI forms are simply modules in this tree.
There is a third way of separating the UI from the business logic and the db. Remember that you UI is a tree of control each containing smaller controls. For example, a form that contain a grid whose some of its cells contains a calendar control. Theoritaclly speaking, you could have a real tiered application who would have 3 tiers, but they would be separated on every level of the UI tree. In that scenario, you would have a business object for the form, that will contain a collection of objects for the grid lines, that will contain a collection of objects for the grid cells. Each of these object would have its related UI “tier” – meaning, a control that is bind to it. It would also have its bound database entity, but with tabular databases, the question is, how to represent the relations between the objects. And I have no clear answer for that. Maybe I’ll try it on my next system.
Event-based Framework
I know this might be seen as an overkill to some, but hear me out. why events? This is simple. An eCommerce order form (AKA ‘shopping cart’), for example, can be viewed as one module which includes the order date and number, the customer and a collection of the products on this order. The inventory, on another side of the system, is another major module holding all the products and their quantity in the warehouse. When an order is placed, you would want to update the inventory with the products sold, so the quantity in stock could be decremented. The simplistic way would be to have the inventory module exposing methods, and call them directly when the order is placed. The problem with that, is that some day – and you can count on this – some one will come up with a new requirement for more modules to be updated on an order. For example, an email module for sending an email to the manager reporting the sale. Now, for every new module that needs update, the developers will need to change the order module and add a new call to the new module. While the young, talented programmer looks at this as a non issue, we experienced architects know how much it can be simplified with an event-based framework. In such a framework, placing of an order would publish an event to the whole system. Not only would the Inventory module subscribe to it, but any new module that wishes to act upon this trigger, would subscribe too. So the amount of work needed to accommodate new requirements is minimized at least by half: there is no need to touch the order module. In reality, since software complexity tends to be exponential, the decrease in work is in much, much more.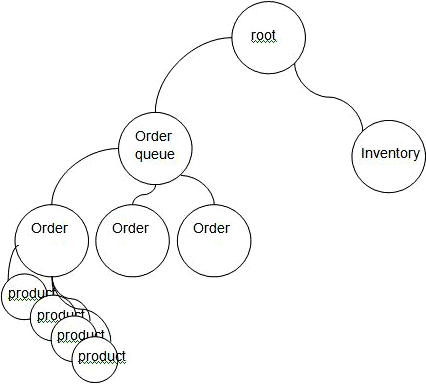
When you do go ahead and write your publisher-subscriber framework, remember that you might take one more small step that will pay off big time later. As I explained in the “Tiered Framework” section, every system is inherently based on a tree-like architecture. Imagine, for example, that a sudden price change occured for one of your products. Different requirements arrise, one of them being the need to update all orders in queue that contains this product. A simplistic approach would be to search all these orders, find the ones needed a change, and update the prices.
But then, when a new requirement would arise, again we need to touch the source.
In a tree-based architecture, the orders are children of the root, and the products (also called ‘order details’) would be children of the orders.
An event would be published to the root. The products subscribe to ‘price changed’ event, and if an action needed, call the parent order (or better more, publish an event to the parent order) to change the total, the presentation, and do whatever else is needed on such event.
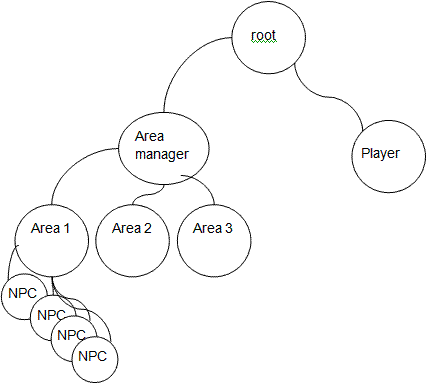
By the way, the same logic works in much more interesting applications – games for example. If a missile was fired in the area, all subscribed NPCs (Non Player Characters) would want to know about this event, so they could evade – and die, if hit was decided. Other modules would like to know that the missile inventory should be decreased, that the event should be reflected in a remote multiplayer session – in short, there is no shortage of wars to win with this frame of mind.
Cache Framework
Maybe one of the most important performance optimizers. From the L2 CPU Cache to the database’s memcached, everyone should have a cache. To be honest, I’m still puzzled as to why it really works so well, and still at awe watching the magnitude of improvement. But it is clear now that this is the biggest performance boosters ever created. And every system should have its own Cache Manager class, which centralizes few important actions: from adding a value to the cache, to retrieving, invalidation, and – very important – single point of overall cache deletion.Error and trace Framework
It is sometimes amazing how this simple module often get ignored until the later stages of the project. But a clear definition at the beginning of the project can do wonders to your ability to find fast bugs and exceptions.There are some nice open source packages that offer a nice set of features. But whatever way you implement it, here are a few key notes I believe worth repeating:
- distinguish between tracing and error reporting. It is not the same. Tracing is used for the development team, or for very problematic client sites. Errors are something else – you need to always report them
- an error is not a bug. If a function cannot calculate a price for this quantity, it might be reported to the user, but not an error. In my view, every error is an Exception. Something that no one foresaw.
- Invest the time to get real time tracing. You’ll thank me later.
Lior Messinger is a software architect based in New York, with about 20 years of experience.
Comments