Structs are a fundamental data type in C# and most other modern programming languages. They are inherently simple, but you might be surprised at how fast things can become more complicated. The problems mostly arise when you have to work with structures created in other languages, either saved on disk or when calling functions in DLLs or COM. In this article I’m going to assume that you know what a struct is, how to define one and the basics of using one. I’m also going to assume that you have a rough idea of how to call an API function using p/Invoke, and what marshalling is all about. If you are unsure of any of this the standard documentation will give you the basics. Many of the techniques described in this article can be extended to any data type.
Layout
In many situations you can simply declare and use a struct without worrying about how it is implemented – specifically how its fields are laid out in memory. If you have to provide structs for consumption by other programs, or use such “foreign” structs, then memory layout matters. What do you think the size of the following struct is?
public struct struct1
{
public byte a; // 1 byte
public int b; // 4 bytes
public short c; // 2 bytes
public byte d; // 1 byte
}
A reasonable answer is 8 bytes, this being the sum of the field sizes. If you actually investigate the size of the struct using:
int size = Marshal.SizeOf(test);
…you will discover (in most cases) that the struct takes 12 bytes. The reason is that most CPUs work best with data stored in sizes larger than a single byte and aligned on particular address boundaries. The Pentium likes data in 16-byte chunks, and likes data to be aligned on address boundaries that are the same size as the data. So for example, a 4-byte integer should be aligned on a 4-byte address boundary, i.e. it should be of the form 4n-1. The exact details aren’t important. What is important is that the compiler will add “padding” bytes to align the data within a struct. You can control the padding explicitly, but notice that some processors throw an exception if you use data that isn’t aligned, and this creates a more complicated problem for .NET Compact users.
To control the layout of a struct you need to use InteropServices, so add:
using System.Runtime.InteropServices;The struct’s layout is controlled by a StructLayout attribute. For example:
[StructLayout(LayoutKind.Sequential)]
public struct struct1
{
public byte a; // 1 byte
public int b; // 4 bytes
public short c; // 2 bytes
public byte d; // 1 byte
}
…forces the compiler to assign the structure sequentially as listed in the definition, which is what it does by default. Other values of LayoutKind are Auto, which lets the compiler determine the layout, and Explicit, which lets the programmer specify the size of each field. Explicit is often used to create sequential memory layouts with no packing, but in most cases it is simpler to use the Pack field. This tells the compiler exactly how to size and align the data that makes up the fields. For example, if you specify Pack=1 then the struct will be organised so that each field is on a byte boundary and can be read a byte at a time – i.e. no packing is necessary. If you change the definition of the struct to:
[StructLayout(LayoutKind.Sequential,
Pack=1)]
public struct struct1
…you will discover that it is now 8 bytes in size, which corresponds to the fields being laid out in memory sequentially with no packing bytes. This is what you need to work with most of the structures defined in the Windows API and C/C++. In most cases you don’t need to use other values of Pack. If you do set Pack=2 then you will find that the size of the struct is now 10 bytes because a byte is added to each of the byte fields to make the entire struct readable in 2-byte chunks. If you set Pack=4 then the size increases to 12 bytes to allow the entire struct to be read in blocks of 4 bytes. After this nothing changes because the pack size is ignored once it is equal to or larger than the alignment used for the CPU – which is 8 bytes for the Intel architecture. The layout of the struct for different pack sizes can be seen in Figure 1.
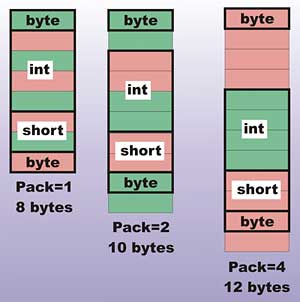
Figure 1: The effect of pack size on layout
It is also worth mentioning that you can modify the way a struct is packed by simply reordering its fields. For example, by changing the field ordering to:
public struct struct1
{
public byte a; // 1 byte
public byte d; // 1 byte
public short c; // 2 bytes
public int b; // 4 bytes
}
…the struct doesn’t need packing and occupies just 8 bytes without the need for any intervention.
Being exact
If you really do want to specify the space allocated to any particular field you can use Exact. For example:[StructLayout(LayoutKind.Explicit)]
public struct struct1
{
[FieldOffset(0)]
public byte a; // 1 byte
[FieldOffset(1)]
public int b; // 4 bytes
[FieldOffset(5)]
public short c; // 2 bytes
[FieldOffset(7)]
public byte d; // 1 byte
}
…produces an 8-byte struct without any padding bytes. In this sense it is equivalent to Pack=1 which is much simpler to use. However Explicit really does give you complete control should you need it. For example:
[StructLayout(LayoutKind.Explicit)]
public struct struct1
{
[FieldOffset(0)]
public byte a; // 1 byte
[FieldOffset(1)]
public int b; // 4 bytes
[FieldOffset(10)]
public short c; // 2 bytes
[FieldOffset(14)]
public byte d; // 1 byte
}
…produces a 16-byte struct with extra bytes following the b field. Until C# 2.0 the main use of an Explicit layout was to provide fixed length buffers for use in DLL calls, for example. You simply cannot declare a fixed size array within a struct because initialising fields isn’t permitted. That is:
public struct struct1
{
public byte a;
public int b;
byte[] buffer = new byte[10];
public short c;
public byte d;
}
…generates an error. If you want a 10-byte buffer one way of doing it is:
[StructLayout(LayoutKind.Explicit)]
public struct struct1
{
[FieldOffset(0)]
public byte a;
[FieldOffset(1)]
public int b;
[FieldOffset(5)]
public short c;
[FieldOffset(8)]
public byte[] buffer;
[FieldOffset(18)]
public byte d;
}
This leaves a block of 10 bytes for the buffer. There are a number of interesting points in this declaration. The first is, why use an offset of 8? The reason is that you can’t start an array on an odd address boundary. If you use 7 you will see a runtime error informing you that the struct cannot be loaded because of an alignment problem. This is important because it means you can cause problems by using Explicit if you don’t know what you are doing. The second is that the entire struct has additional bytes added to the end to bring its size up to a multiple of 8 bytes. The compiler still gets involved with memory allocation. In practice, of course, any external structure that you are trying to convert to a C# struct should be correctly aligned and the problem shouldn’t arise.
Finally it is worth noting that you can’t refer to the 10-byte buffer using the array name, as in buffer[1] etc, because C# thinks that the buffer is unassigned. As you can’t use the array and it causes an alignment problem, a much better way to declare the struct is:
[StructLayout(LayoutKind.Explicit)]
public struct struct1
{
[FieldOffset(0)]
public byte a; // 1 byte
[FieldOffset(1)]
public int b; // 4 bytes
[FieldOffset(5)]
public short c; // 2 bytes
[FieldOffset(7)]
public byte buffer;
[FieldOffset(18)]
public byte d; // 1 byte
}
To access the 10-byte field you have to use pointer arithmetic on buffer – which is of course considered “unsafe”. To allocate a fixed number of bytes to the last field in a struct you can use the Size= field in the StructLayout as in:
[StructLayout(LayoutKind.Explicit,
Size=64)]
As of C# 2.0, fixed arrays are now allowed within structs and this more or less makes the above construction unnecessary. It is worth noting that fixed arrays essentially use the same mechanism, i.e. fixed size allocation and pointers, hence this too is unsafe. If you need the fixed size buffers within a call to a DLL then the probably the best method is to use explicit marshalling for the arrays, which is considered “safe”. Let’s take a look at all three methods in use.
Calling the API
As an example of using structs with layout requirements we can use the EnumDisplayDevices function, which is defined as:BOOL EnumDisplayDevices(
LPCTSTR lpDevice,// device name
DWORD iDevNum,// display device
PDISPLAY_DEVICE lpDisplayDevice,
// device information
DWORD dwFlags // reserved
);
This is fairly easy to convert into a C# declaration:
[DllImport(“User32.dll”,
CharSet=CharSet.Unicode )]
extern static bool
EnumDisplayDevices(
string lpDevice,
uint iDevNum,
ref DISPLAY_DEVICE
lpDisplayDevice,
uint dwFlags);
The DISPLAY_DEVICE structure is defined as:
typedef struct _DISPLAY_DEVICE {
DWORD cb;
WCHAR DeviceName[32];
WCHAR DeviceString[128];
DWORD StateFlags;
WCHAR DeviceID[128];
WCHAR DeviceKey[128];
} DISPLAY_DEVICE, *PDISPLAY_DEVICE;
It is clear that it contains four fixed-sized character arrays. This can be translated into C# using an Explicit layout as:
[StructLayout(LayoutKind.Explicit,
Pack = 1,Size=714)]
public struct DISPLAY_DEVICE
{
[FieldOffset(0)]
public int cb;
[FieldOffset(4)]
public char DeviceName;
[FieldOffset(68)]
public char DeviceString;
[FieldOffset(324)]
public int StateFlags;
[FieldOffset(328)]
public char DeviceID;
[FieldOffset(584)]
public char DeviceKey;
}
Notice the use of Size= to specify the storage needed by the DeviceKey field. When this is used in an actual call:
DISPLAY_DEVICE info =
new DISPLAY_DEVICE();
info.cb = Marshal.SizeOf(info);
bool result = EnumDisplayDevices(
null,
0,
ref info,
0);
…all you can directly access are the first characters in each of the buffers using the field variables. For example, DeviceString holds the first character of the device string buffer. If you want to get at the rest of the buffer you have to get a pointer to DeviceString and use pointer arithmetic to step through the array.
If you are using C# 2.0 then a simpler solution is to use a fixed array, as in:
[StructLayout(LayoutKind.Sequential,
Pack = 1)]
public unsafe struct DISPLAY_DEVICE
{
public int cb;
public fixed char DeviceName[32];
public fixed char DeviceString[128];
public int StateFlags;
public fixed char DeviceID[128];
public fixed char DeviceKey[128];
}
Notice that now the struct has to be declared as “unsafe”, but now after the API call we can access the character arrays without using pointers. Pointers are still used behind the scenes, however, and any code that uses the arrays has to be marked as unsafe.
The third and final method is to use custom marshalling. Many C# programmers don’t realise that marshalling isn’t just about the way that the system types data for passing to DLLs – instead it is an active process that copies and transforms the managed data. For example, if you choose to pass a reference to an array of typed elements then you can ask for it to be marshalled as a value array and the system will convert it into a fixed length buffer, and back to a managed array, without any extra effort on your part.
In this case all we have to do is add the MarshalAs attribute, specify the type and size of the arrays:
[StructLayout(LayoutKind.Sequential,
Pack = 1, CharSet = CharSet.Unicode)]
public struct DISPLAY_DEVICE
{
public int cb;
[MarshalAs(
UnmanagedType.ByValArray,
SizeConst=32)]
public char[] DeviceName;
[MarshalAs(
UnmanagedType.ByValArray,
SizeConst=128)]
public char[] DeviceString;
public int StateFlags;
[MarshalAs(
UnmanagedType.ByValArray,
SizeConst = 128)]
public char[] DeviceID;
[MarshalAs(
UnmanagedType.ByValArray,
SizeConst = 128)]
public char[] DeviceKey;
}
What happens in this case is that, when you make the DLL call, the fields are marshalled by creating unmanaged buffers of the correct size within the copy of the struct that is to be passed to the DLL function. When the function returns the unmanaged buffers are converted into managed char arrays and the field variables are set to reference them. As a result when the function is complete you will discover that the struct has char arrays of the correct size containing the data.
Clearly, as far as calling a DLL is concerned, the custom marshal is the best option as it produces safe code – although using p/Invoke to call a DLL isn’t really safe in any sense.
Serialising structs
Now that we have looked at the complicated question of how to control the memory layout of a struct, it is time to discover how to get at the bytes that make up a struct, i.e. how do we serialise a struct? There are many ways of doing this job and the most commonly encountered uses Marshal.AllocHGlobal to allocate an unmanaged buffer from the global heap. After this everything is achieved using memory transfer functions such as StructToPtr or Copy. For example:public static byte[]
RawSerialize(object anything)
{
int rawsize =
Marshal.SizeOf(anything);
IntPtr buffer =
Marshal.AllocHGlobal(rawsize);
Marshal.StructureToPtr(anything,
buffer, false);
byte[] rawdata = new byte[rawsize];
Marshal.Copy(buffer, rawdata,
0, rawsize);
Marshal.FreeHGlobal(buffer);
return rawdata;
}
In fact there is no need to do so much bit moving, as it is fairly easy to move the bytes in the struct directly to the byte array without the need for an intermediate buffer. The key to this generally useful technique is the GCHandle object. This will return a Garbage Collection handle to any managed data type. If you ask for a “pinned” handle, the object will not be moved by the garbage collector, and you can use the handle’s AddrOfPinnedObject method to retrieve its starting address. For example, the RawSerialise method can be rewritten:
public static byte[]
RawSerialize(object anything)
{
int rawsize =
Marshal.SizeOf(anything);
byte[] rawdata = new byte[rawsize];
GCHandle handle =
GCHandle.Alloc(rawdata,
GCHandleType.Pinned);
Marshal.StructureToPtr(anything,
handle.AddrOfPinnedObject(),
false);
handle.Free();
return rawdata;
}
This is both simpler and faster. You can use the same methods to deserialise data in a byte array into a struct, but rather than considering this example it is more instructive to examine the related problem of reading a struct from a stream.
Structs from streams
A fairly common requirement is to read a struct, possibly written using some other language, into a C# struct. For example, suppose you need to read in a bitmap file, which starts with a file header, followed by a bitmap header and then the bitmap data. The file header structure is easy to translate:[StructLayout(LayoutKind.Sequential,
Pack = 1)]
public struct BITMAPFILEHEADER
{
public Int16 bfType;
public Int32 bfSize;
public Int16 bfReserved1;
public Int16 bfReserved2;
public Int32 bfOffBits;
};
A function that will read any structure available as a stream and return a struct can be written without the need for Generics:
public object ReadStruct(FileStream
fs, Type t)
{
byte[] buffer =
new byte[Marshal.SizeOf(t)];
fs.Read(buffer, 0,
Marshal.SizeOf(t));
GCHandle handle =
GCHandle.Alloc(buffer,
GCHandleType.Pinned);
Object temp =
Marshal.PtrToStructure(
handle.AddrOfPinnedObject(),
t);
handle.Free();
return temp;
}
You should recognise the use of the GCHandle object to enable the data to be transferred. The new feature is the use of a Type object to specify the type of the struct being read in. Unfortunately there is no way to use this to return an object of the specified type, so we need to use a cast when calling the function, as in:
FileStream fs = new FileStream(
@”c:\1.bmp”,
FileMode.Open,
FileAccess.Read);
BITMAPFILEHEADER bmFH =
(BITMAPFILEHEADER)ReadStruct(
fs, typeof(BITMAPFILEHEADER));
If we want to avoid the cast then we need to create a generic method. This is just a matter of introducing a type parameter <T> and then using it throughout the method as if it were the type of the struct:
public T ReadStruct <T> (
FileStream fs)
{
byte[] buffer = new
byte[Marshal.SizeOf(typeof(
T ))];
fs.Read(buffer, 0,
Marshal.SizeOf(typeof(T)));
GCHandle handle =
GCHandle.Alloc(buffer,
GCHandleType.Pinned);
T temp = (T)
Marshal.PtrToStructure(
handle.AddrOfPinnedObject(),
typeof(T));
handle.Free();
return temp;
}
Notice that now we have to cast the object returned by PtrToStructure to the type in the method rather than in the method call, which becomes:
BITMAPFILEHEADER bmFH =
ReadStruct
<BITMAPFILEHEADER>(fs);
It is interesting to contemplate just how much better the generic method is than the method that needs the explicit cast.
Manual marshalling
Marshalling works so well most of the time that there is a tendency to forget that it is doing anything at all. However, as soon as you hit something even slightly out of the ordinary you might be surprised at what happens when it stops working. For example, some API calls need you to pass a pointer to a pointer to struct. You already know how to pass a pointer to a struct – it’s just pass by ref – and this might lead you to believe that a simple modification will allow you to pass a pointer to that pointer. But things are more complicated than you might expect. Let’s look at this a step at a time.In the AVIFileCreateStream API call the last two parameters are passed as pointers to an IntPtr and a struct respectively:
[DllImport(“avifil32.dll”)]
extern static int AVIFileCreateStream(
IntPtr pfile, ref IntPtr pavi,
ref AVISTREAMINFO lParam);
To use this API call you would use:
result = AVIFileCreateStream(pFile,
ref pStream, ref Sinfo);
At this point, given our earlier examples, it would appear easy to take over the marshalling of the pointer to the struct and do it manually. For example, what could be wrong with changing the declaration to:
[DllImport(“avifil32.dll”)]
extern static int AVIFileCreateStream(
IntPtr pfile,
ref IntPtr pavi,
IntPtr lParam);
However, if you try to use it by passing the address of the pinned structure:
GCHandle handle =
GCHandle.Alloc(Sinfo,
GCHandleType.Pinned);
result = AVIFileCreateStream(pFile,
ref pStream,
handle.AddrOfPinnedObject());
handle.Free();
…the result is a runtime error as shown in Figure 2.
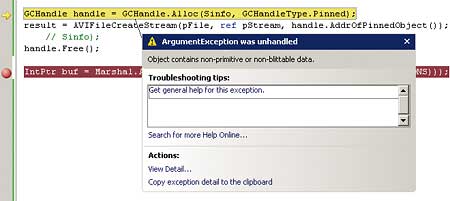
Figure 2: Protected memory runtime error
The reason is that while you are indeed passing a pointer to the start of the struct, that struct is in managed memory, and unmanaged code cannot access it without generating a protection error. What we are forgetting is that standard marshalling does much more for us than generate addresses to use as pointers. The default marshalling for all parameters passed by ref also makes a copy of the entire data in unmanaged memory before deriving a pointer. It then copies the unmanaged memory back to the managed type when the function ends.
It isn’t difficult, and is indeed quite useful, to write a function that does the same job as default marshalling:
private IntPtr MarshalToPointer(
object data)
{
IntPtr buf = Marshal.AllocHGlobal(
Marshal.SizeOf(data));
Marshal.StructureToPtr(data,
buf, false);
return buf;
}
This simply returns an IntPtr to an area of the global heap that contains a copy of the data. The only problem with this function is that you have to remember to release the allocated heap memory after use. For example:
IntPtr lpstruct =
MarshalToPointer(Sinfo);
result = AVIFileCreateStream(pFile,
ref pStream, lpstruct);
Marshal.FreeHGlobal(lpstruct);
…works exactly like default marshalling. But don’t forget that lpstruct is itself still being marshalled as a pass-by-value integer. To copy the result back to the struct an additional function is required:
private object MarshalToStruct(
IntPtr buf,Type t)
{
return Marshal.PtrToStructure(
buf, t);
}
Now that we have mastered the manual marshalling of a simple pointer to a struct, the next step is a pointer to a pointer to a struct. Surprisingly this requires nothing new because the struct-to-pointer function will actually convert any data type to an unmanaged pointer – including a pointer.
The function AVISaveOption is a suitable example, as it needs two pointers to pointers as parameters:
[DllImport(“avifil32.dll”)]
extern static int AVISaveOptions(
IntPtr hWnd,
int uiFlags,
int noStreams,
IntPtr ppavi,
IntPtr ppOptions);
In fact the ppavi parameter is a pointer to a handle (which is itself a pointer), and the ppOptions is a pointer to a pointer to a struct. To call this function we first need the struct:
AVICOMPRESSOPTIONS opts =
new AVICOMPRESSOPTIONS();
You can lookup the definition of the structure in the standard AVI documentation.
Next we need the marshalled pointer to the struct:
IntPtr lpstruct =
MarshalToPointer(opts);
…and then the pointer to the pointer:
IntPtr lppstruct =
MarshalToPointer(lpstruct);
…followed by the pointer to the handle:
IntPtr lphandle =
MarshalToPointer(pStream);
The call to the API function is now simple:
result = AVISaveOptions(m_hWnd,
ICMF_CHOOSE_KEYFRAME |
ICMF_CHOOSE_DATARATE, 1,
lphandle, lppstruct);
…where the other parameters and constants aren’t of any great interest to us and you can find more details in the API’s documentation.
When the function completes, all that is left to do is transfer the data in the unmanaged buffer back into the managed struct:
opts = (AVICOMPRESSOPTIONS
)MarshalToStruct(lpstruct,
typeof(AVICOMPRESSOPTIONS));
You have to be careful to use the pointer to the struct and not the pointer to the pointer! Finally we can free all of the unmanaged memory we used:
Marshal.FreeHGlobal(lpstruct); Marshal.FreeHGlobal(lppstruct); Marshal.FreeHGlobal(lphandle);This might all seem complicated. Using pointers-to-pointers is never an easy thing to do, and it is one of the reasons that C# makes sure that when you do use pointers, you mark the code as unsafe. However, you might like to contemplate just how safe this sort of juggling is, and all without an unsafe block in sight.
On the other hand the general principles are very simple. When you pass anything by ref to an API it has to be copied to unmanaged memory, and the address of this memory is passed to the function.
Normally default marshalling takes care of this and you can ignore it – but it still happens. If you need to go beyond what is provided by the marshalling attributes then you have to perform this copying explicitly.
Comments