This article was originally published in VSJ, now part of Developer Fusion
At the Professional Developers Conference in 2005, Microsoft unveiled a new library called Windows Workflow Foundation. Windows Workflow Foundation, or WF as it has become known, shipped in .NET 3.0 along with Windows Presentation Foundation (WPF) and Windows Communication Foundation (WCF). The strange thing was that no one really knew what to make of WF. WPF was obviously a replacement for GDI / Windows Forms for building rich client applications.
WCF was obviously a revised networking stack to replace technologies like ASP.NET Web Services (ASMX) and .NET Remoting. WF didn’t appear to be replacing anything that we already had but was something completely new. Now, three and a half years later, we are on the verge of the first beta of a new version of WF, version 4.0, which promises many improvements to the WF infrastructure at a cost of a radical change to the API and tools. So it is a fitting time to take stock of what Microsoft was trying to achieve with WF and look at where it fits into application architectures now and in the future.
What problem was WF trying to solve?
WF didn’t come about from a group of bright people sitting in a room together trying to come up with “the next great thing”. Several groups within Microsoft had independently realised they required workflow-like functionality including the SharePoint, BizTalk and CRM teams. The decision was made to build this functionality once in such a way that all interested parties could use the resulting framework.
So what was this functionality that all these teams all come to realise they needed? It fundamentally came down to three issues: processing transparency, long running execution and non-linear flow. Let’s have a look at each of these in turn.
Processing transparency
Code is hard to read. Even the best code is hard to read if you didn’t write it. Generally when a developer is trying to explain what a system does they don’t show them the code, they draw a diagram. This is commonly what happens in system design, diagrams are drawn to show intention and then the system is built. However, inevitably during development, original designs get altered due to changing requirements or greater insight as to what is necessary for the code to do. Unfortunately the design diagrams are often left in their original state and so the only real truth of the system is in the code itself. But code is hard to read. This tension became especially relevant on the back of the collapse of Enron when the US government introduced a rigorous audit infrastructure called Sarbanes-Oxley. Suddenly companies were required to be able to prove what their IT systems did.
Processing transparency has another benefit beyond understanding the code’s intent. If the processing can be easily understood then maybe new functionality can be built by people who are not hard-core developers as long as they are constrained in some way as to how they build the system.
Long running execution
What “long running” means to you depends on your background. For many developers long running means processing for an hour; however, for others long running means several weeks or months. This latter definition has specific issues that are not necessarily apparent when your processing takes a maximum of an hour. To have processing that spans months you fundamentally cannot rely on the same process, or even machine, running the processing to completion. This means that the state of the processing must be saved somewhere during execution. But more than that, long running execution generally means that the processing is spending a great deal of time waiting for external events to occur. During this time the processing is idle and there is no point it consuming memory and threads. Therefore, we should have some means of not only saving the state but also unloading the saved processing from memory. The corollary of this is we need some mechanism of restoring the processing into memory when one of the external events it is waiting on occurs. Writing the plumbing to achieve this is certainly non-trivial.
Non-linear flow
Most applications have processing that is modelled on a sequence of actions that get executed in order with maybe some loops and branches – there is an inevitable flow of execution towards an endpoint. Unfortunately processing in the real world often doesn’t exhibit the same characteristics.
As I write this article I have an expense claim being processed for a training course I delivered. In the past two hours I have had the claim sent back to me twice with questions regarding various items on the claim. In theory, myself and the person processing the claim could spend eternity sending this expense claim back and forth between us. There is no fundamental reason why processing has to move to a conclusion here, the expense claim is simply moving back and forth between two valid states of the system. This kind of processing, all too common when humans are involved in the flow, is far better modelled using a finite state machine. However, building this for every human-driven piece of processing I model would be tedious and error prone to say the least.
How does WF solve these issues?
The reason WF was built, then, was to provide a framework that solves these real world problems. If WF provides solutions to the above three problems, how does it do it?
Processing transparency
WF introduces a visual designer to assemble processing from reusable units of work called activities. The designer, in essence, gives you a visual domain specific language (DSL) for modelling processing flow. Figure 1 shows an example of a workflow in the workflow designer. The critical thing here is that what you see in the designer is not just a diagram describing the code, it is the code. This means we get the visual view that makes the code easier to understand but there is no way for this view to get out of alignment with the code.
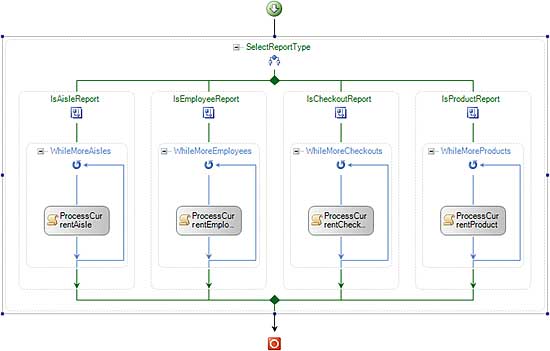
Figure 1: A workflow in the designer
The designer can also be re-hosted in your own application. In this situation you can constrain the activities that are available in the designer to provide a protected environment for less technical people to assemble workflows. It must be said, however, that in the current 3.5 build of WF designer re-hosting is far harder than the team would like and this is one of the issues being addressed in WF 4.0.
Long running execution
Workflow execution takes place under the control of a runtime environment. Each activity is executed by this runtime and it tells the runtime whether it is finished or waiting for some external event to happen. The runtime therefore knows when a particular instance of a workflow has no work to do. It also has a pluggable persistence layer which the runtime uses, in conjunction with the knowledge that the workflow is idle, to save the state of the workflow and unload it from memory. However, each workflow is identified by a GUID known as the Workflow Instance Id. Any external event must present this GUID to the workflow runtime which allows the runtime to reload the relevant workflow into memory.
Non-linear flow
WF can certainly model sequential flow of execution of activities. It also comes with a different execution model based on state machine. Here you define the valid states of the processing and what events trigger state transition from one state to another. The workflow runtime and state machine top level workflow activity manage the state machine based execution together. Figure 2 shows a state machine workflow in the design view.
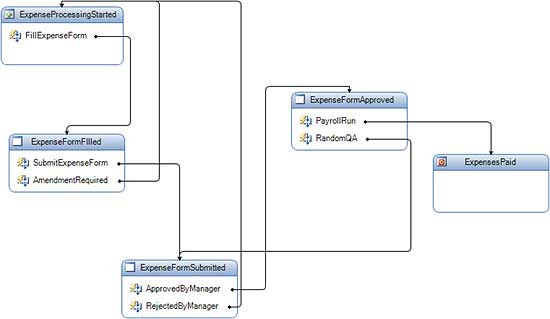
Figure 2: A state machine workflow
Using workflow in your applications
Now that we have seen what workflow brings to the .NET platform what does it really mean for your applications: where is it appropriate to use? What are your responsibilities? What should you be careful of?
The workflow runtime has been built such that it can be hosted in any .NET process. Workflow therefore can be used for a variety of types of applications. The critical thing is to make sure you are using it to solve a problem it was designed to solve – replacing all of your application “if” statements with workflows containing IfElseActivties would be a performance disaster. The use to which you put workflow depends on the type of application hosting it.
Smart Client
There are two common scenarios for using workflow in smart clients. The first is where part of the smart client’s functionality is essentially a complex wizard. In this scenario you can use workflow to script a path through the wizard screens based on the user’s choices. The second scenario takes advantage of ability to query what data a workflow is waiting for. Based on this you can drive which pieces of a UI are enabled based on the state of an underlying workflow. State machine workflow models this well as it is inherently event driven.
ASP.NET
Primarily, in ASP.NET, workflow is used to drive page flow through web applications. However, sometimes you will find yourself having to fight either the sequential or state machine workflow execution models to give you the functionality you need. Fortunately the workflow team have released a sample called Page Flow Workflow that provides a new execution model specifically targeted at web applications.
Windows Service
Running workflows in windows services is the workhorse for workflow deployment. Any service side long running processing is an ideal candidate for running inside a windows service. The main thing that windows services give you over ASP.NET is that the stability of the process is more reliable as there is no AppDomain or worker process recycling which are inherent in the ASP.NET environment. Even though workflow was designed to be able to withstand process recycling it’s generally a good idea to give it a stable process as possible. When you add into the mix that, as of .NET 3.5, workflows can be WCF endpoints, you get a good mixture of stability and accessibility with running workflows in windows services. So, for example, running long running processing such as mortgage application processing is a good candidate for windows service workflow hosting.
So let’s say that you have decided that workflow is a good fit with your requirements. What exactly are you responsible for when building a workflow based application? You really have two issues to consider: custom activities and workflow hosting.
Custom Activities
When you bring up the workflow designer in Visual Studio you will notice that in the toolbox there are a large number of activities that come out of the box. This set of activities is known as the Standard Activity Library. However, if you look through these activities you will notice that their roles are flow control (IfElseActivity, WhileActivity, ParallelActivity, etc) and infrastructure (TransactionScopeActivity, CompensatableSequenceActivity, ThrowActivity, etc). Nothing in here models your business domain. Therefore, if you are really going to leverage value from the workflow infrastructure you need to create reusable components that model units of work from your world.
Writing custom activities ranges from the very simple to the very complex. A basic activity that does not wait on external events to complete its work requires very little special infrastructure around the processing it performs. On the other hand, asynchronous activities that fit in with the various places they might be used can be very complex to get right. Unfortunately, for long running execution you will often want to write activities that are asynchronous to allow your workflow to be unloaded while it is waiting. Fortunately writing asynchronous activities is going to be made much simpler in WF 4.0.
Workflow hosting
In a workflow driven application the hosting process has two fundamental tasks: creating and starting the workflow runtime. This is the bare minimum of what it must do; however, its job is normally far more complex. The hosting process needs to configure the services that the runtime uses to perform its work, such as persistence; it needs to trigger the creation of new workflow instances; it needs to mediate external communication into running workflows. All of this can be non-trivial.
Hosting in smart clients and windows services is fairly straightforward as the lifetime of the workflow runtime is generally tied to the lifetime of the process. In ASP.NET hosting there are extra considerations. Firstly, by default, workflows execute on threadpool threads. These are the same threads that ASP.NET executes on and therefore ASP.NET ends up fighting the workflow runtime for threadpool threads. To get around this issue you have to replace the standard workflow scheduling infrastructure with a manual scheduler that allows you to explicitly run the workflow on a specific thread (normally the request thread). Secondly, asynchronous activity processing has complexities with ASP.NET hosting. In ASP.NET hosting you tie the lifetime of the workflow runtime to the web application’s AppDomain.
This means that when a worker process is recycled the workflow runtime will not start running until the next request comes in for the web application. The problem is that often, when a workflow is waiting for an external event, you put in place a timeout to allow you to take action if that event does not occur. If the workflow runtime is not running it will not notice that a timeout has occurred.
Conclusion
If you have processing that needs transparency, long running execution or non sequential flow you should definitely consider WF as part of your architecture. If it fits your requirements it will save you writing a great deal of plumbing. Just be aware however, of the three frameworks that shipped with .NET 3.0, WF is definitely the one that requires you to build most infrastructure on top of it to get the most out of it.
Comments