In the age of Object Relational Mapping frameworks (ORMs) it seems unusual to ever get “close to the metal” when it comes to persisting data. Developers are getting quite used to being abstracted away from the underlying data access technologies. However there are times when having a good understanding of what’s going on under the covers can allow you to look for alternative solutions when the ORM layer isn’t going to be as efficient as you need for a particular scenario. (This is actually true for all abstractions, not just ORMs.)
In a project I worked on about 5 years ago I implemented my own ORM. The application it was being developed for needed to save large sets of data to the database, anywhere between 100,000 and 1,000,000 records in a batch. For various reasons, all of this needed to operate within the ORM code-base; that is to say it wasn’t going to be possible to use a SQL Server DTS package to load the data. Running some performance tests showed that saving the data on a row by row basis by firing off multiple INSERT statements just wasn’t going to cut the mustard.
The most efficient way to accomplish this turned out to be the SqlBulkCopy class. Unfortunately there isn’t a simple way to get SqlBulkCopy to process through a collection of business entities. This article will show you how you can use SqlBulkCopy with any set of classes to insert new data into a database very quickly. (As an aside, this isn’t the code that I wrote all those years ago – this article takes advantage of .NET framework features that weren’t available back when the original framework was developed, which make things even better than before.)
Setting the scene
Consider a database called MostWanted with the following table defined within it:
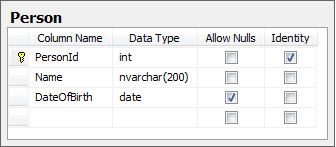
A very simple class could be used to represent this in C#:
public class Person { public int PersonId { get; set; } public string Name { get; set; } public DateTime? DateOfBirth { get; set; } }
If you want to follow along, there’s a script in the attached source code to create the database and table.
Using SqlBulkCopy
There are 4 methods on the SqlBulkCopy API that write data to a database:
public void WriteToServer(IDataReader reader); public void WriteToServer(DataTable table); public void WriteToServer(DataTable table, DataRowState rowState); public void WriteToServer(DataRow[] rows);
The last three of them are closely tied to DataTable-centric classes that were introduced with the first version of the .NET framework. Without copying the data from the objects into a completely different format, these particular methods aren’t going to be any use.
That leaves the first method that takes an IDataReader instance. Ideally it would be possible to create a generic ObjectDataReader<Person> and use that to feed WriteToServer with a set of objects. Sadly this doesn’t exist, so you’re going to have to implement your own.
IDataReader itself isn’t that big:
public interface IDataReader : IDisposable, IDataRecord { int Depth { get; } bool IsClosed { get; } int RecordsAffected { get; } void Close(); DataTable GetSchemaTable(); bool NextResult(); bool Read(); }
But as you can see, it also implements IDisposable (not a big deal) and IDataRecord (a slightly bigger deal). Putting the slightly menacing IDataRecord interface aside for now, this is what a generic implementation of IDataReader might look like:
public class ObjectDataReader<TData> : IDataReader { private IEnumerator<TData> dataEnumerator; public ObjectDataReader(IEnumerable<TData> data) { this.dataEnumerator = data.GetEnumerator(); }
The constructor takes an enumerable of whatever generic type the data reader is constructed with. This is used to get an enumerator that will be used to iterate through the data.
public bool Read() { if (this.dataEnumerator == null) { throw new ObjectDisposedException("ObjectDataReader"); } return this.dataEnumerator.MoveNext(); }
Other than making sure the instance hasn’t been disposed, Read just moves the enumerator onto the next item and returns the result of doing so. This will be true if there was another item to move to, or false if the enumerator has run out of items.
public void Dispose() { this.Dispose(true); GC.SuppressFinalize(this); } protected virtual void Dispose(bool disposing) { if (disposing) { if (this.dataEnumerator != null) { this.dataEnumerator.Dispose(); this.dataEnumerator = null; } } }
The dispose methods follow the standard Dispose pattern – the only thing that needs cleaning up there is the enumerator that was created during the constructor call.
public void Close() { this.Dispose(); } public bool IsClosed { get { return this.dataEnumerator == null; } }
IsClosed just checks to see if the data reader has been disposed by checking if the enumerator is null, and Close is just a wrapper for Dispose. As an aside, I don’t really like there being two ways to dispose an object, but it’s in the interface so it’s best to implement it.
The rest of the IDataReader members (GetSchemaTable, NextResult, Depth and RecordsAffected) aren’t relevant to this implementation.
There’s nothing really complicated there; all the code does so far is iterate through the values yielded by an enumerator, which is nothing more than a foreach statement can do for us. That’s why we have to implement IDataRecord as well, and this is where the fun starts.
IDataRecord
The IDataRecord interface provides access to the values held within the current record the IDataReader is pointing to. In a traditional sense IDataRecord would be responsible for returning values from the columns returned by a database query or the columns in a data table. This column-centric view of the world is a bit of a problem, as you’ll see very shortly.
The IDataRecord interface contains a lot of members, but most of them aren’t called during the SqlBulkCopy process. In fact, of the 24 properties and methods it defines, only 3 need to be implemented:
int FieldCount { get; } int GetOrdinal(string name) object GetValue(int i)
GetValue is the most important method as it is the one that SqlBulkCopy calls to get values from each of the properties. Notice that GetValue only takes an integer parameter: the ordinal position of the column to read. This is the problem I alluded to earlier as this doesn’t make much sense in an object-based context where properties need to be read.
FieldCount is just used to return the number of columns (or properties) on the current record and GetOrdinal is a method that supports GetValue by providing the ordinal index for a column/property name.
So somehow you need to map the properties of the class to an ordinal index value. The first step to accomplishing this is to use reflection to find all the readable properties on the type of class:
public ObjectDataReader(IEnumerable<TData> data) { this.dataEnumerator = data.GetEnumerator(); var propertyAccessors = typeof(TData) .GetProperties(BindingFlags.Instance | BindingFlags.Public) .Where(p => p.CanRead) .Select((p, i) => new { Index = i, Property = p, Accessor = CreatePropertyAccessor(p) }) .ToArray();
This ugly looking code creates an anonymous type for each property defined on TData, comprising the ordinal index of the property, the PropertyInfo for the property and an accessor for the property created by a method called CreatePropertyAccessor. CreatePropertyAccessor is a method that takes a PropertyInfo and creates a delegate capable of reading from the property for an instance of the class. You’ll see this method implemented shortly.
The rest of the constructor just creates two lookups:
- The first is an array of the property accessors – these are stored in the order they were discovered in the class, i.e. ordinal order.
- The second is a dictionary keyed on property names, the values being the ordinal index of the property in the array lookup.
this.accessors = propertyAccessors.Select(p => p.Accessor).ToArray(); this.ordinalLookup = propertyAccessors.ToDictionary( p => p.Property.Name, p => p.Index, StringComparer.OrdinalIgnoreCase); }
We now have enough information to implement the three methods of IDataRecord. FieldCount is simple – it’s just the number of property accessors that have been generated.
public int FieldCount { get { return this.accessors.Length; } }
GetOrdinal is just a case of looking up in the dictionary to obtain the ordinal index of the property with the given name. Just to be safe there’s a check to ensure that there is a property with a matching name.
public int GetOrdinal(string name) { int ordinal; if (!this.ordinalLookup.TryGetValue(name, out ordinal)) { throw new InvalidOperationException("Unknown parameter name " + name); } return ordinal; }
GetValue simply gets the accessor at the given ordinal index and executes it, passing in the current instance of the class. The accessor will return the value of the property.
public object GetValue(int i) { if (this.dataEnumerator == null) { throw new ObjectDisposedException("ObjectDataReader"); } return this.accessors[i](this.dataEnumerator.Current); }
Creating the accessors
In theory, having the PropertyInfo for the class’s properties would be enough for us to read property values as we could just use PropertyInfo.GetValue. However given that there is an overhead with using reflection and performance is a consideration, CreatePropertyAccessor generates an accessor that is compiled at runtime for each of the properties using expression trees. Here’s the implementation:
private Func<TData, object> CreatePropertyAccessor(PropertyInfo p) { // Define the parameter that will be passed - will be the current object var parameter = Expression.Parameter(typeof(TData), "input"); // Define an expression to get the value from the property var propertyAccess = Expression.Property(parameter, p.GetGetMethod()); // Make sure the result of the get method is cast as an object var castAsObject = Expression.TypeAs(propertyAccess, typeof(object)); // Create a lambda expression for the property access and compile it var lamda = Expression.Lambda<Func<TData, object>>(castAsObject, parameter); return lamda.Compile(); }
Using ObjectDataReader
Here’s a demo command line application illustrating how the ObjectDataReader class could be used in conjunction with SqlBulkCopy to insert a randomly generated set of people into the MostWanted database:
namespace SqlBulkCopyExample { using System; using System.Collections.Generic; using System.Data; using System.Data.SqlClient; using System.Linq; class Program { static void Main(string[] args) { var people = CreateSamplePeople(); using (var connection = new SqlConnection( "Server=.;Database=MostWanted;Integrated Security=SSPI")) { var bulkCopy = new SqlBulkCopy(connection); bulkCopy.DestinationTableName = "Person"; bulkCopy.ColumnMappings.Add("Name", "Name"); bulkCopy.ColumnMappings.Add("DateOfBirth", "DateOfBirth"); connection.Open(); using (var dataReader = new ObjectDataReader<Person>(people)) { bulkCopy.WriteToServer(dataReader); } } } private static IEnumerable<Person> CreateSamplePeople(int count) { return Enumerable.Range(0, count) .Select(i => new Person { Name = "Person" + i, DateOfBirth = new DateTime( 1950 + (i % 50), ((i * 3) % 12) + 1, ((i * 7) % 29) + 1) } }; } } }
Note that if your database columns and object properties are stored in exactly the same order, you might get away without the column mappings, however it is probably best to be explicit about which columns map to which properties. If you have named your entity properties differently to your database columns, you can use this mapping process to indicate which columns a property should map to.
Performance Comparison
The sample project attached to this article runs the bulk insert process for 10,000 records, then inserts them one by one using standard SQL INSERT statements. On my laptop the following timings are obtained:
- SqlBulkCopy: 57ms
- Individual inserts: 2159ms
Quite a stark difference.
Summary
Whilst you might be using an ORM to perform the majority of your data access, ADO.NET still provides some features that can significantly improve performance. Hopefully this article has shown how SqlBulkCopy can be used in a generic way without the need to write large swathes of custom code for each class that you want to write to the database.
The complete source code for this article can be downloaded here.
Comments