Recently there has been a shift in the advancement of hardware. Your computer’s speed is not double what your previous computer’s speed was. Whereas before all of that extra silicon meant faster and faster processors, now it means more and more cores. Note that for the purposes of this article, multiple CPUs will be treated as the equivalent of multiple cores (and vice versa).
Most developers I know are running on at least a dual-core machine. Soon it will be impossible to buy a single-core machine, and it will be normal to be running on 8-core if not more. Yet, if I ask you how your software application takes advantage of multiple cores, most of you will not have a satisfactory answer. The satisfactory answer would include describing how the more cores a machine has, the faster your code executes and the better it scales. There is an initiative at Microsoft called the Parallel Computing Initiative, which encompasses dealing with this issue amongst many others in a wider scope. In this article I would like to focus specifically on what this means to .NET developers, and in particular how to achieve parallelism in managed applications.
A couple of months ago, Microsoft released the December Community Technology Preview (CTP) of the Parallel Extensions to the .NET Framework v3.5 (affectionately referred to in this article as “Parallel Extensions”). It is essentially a .NET library (System.Threading.dll) that you can think of as a user-mode runtime that supports parallelism in any .NET language without compiler or CLR changes. Unless you like working from the command line, you will also need the recently released Visual Studio 2008.
Imperative Task Parallelism
Don’t worry too much about the title of this section, because it’s essentially all about using the Task and TaskManager class. The way we run work items today is by creating Threads via the explicit mechanism shown here:
Thread t = new Thread(DoSomeWorkMethod); t.Start(someInputValue);
If we had 10 work items that could potentially take advantage of parallelisation, we would be creating 10 threads with the approach above. This is not ideal because running computationally-intensive threads that outnumber the number of cores on a machine is itself not ideal due to the context switching, invalidation of each thread’s cache and memory required for each thread’s stack. An alternative is to use the .NET ThreadPool class as per the following corresponding code snippet:
ThreadPool.QueueUserWorkItem(
DoSomeWorkMethod, someInputValue);
If we consider that we have 10 potential work items, using the ThreadPool is likely better than explicitly using a Thread from a performance and scalability perspective, however, it lacks the richness of the full API. In other words, once we have queued a work item, we do not get a reference to it and there is no explicit support for knowing when it completed, or for blocking until it completes or for cancelling it, or for identifying it in the debugger via some sort of ID etc. With the Parallel Extensions, we get a new class that we can use in a similar way as we use Threads today, and with semantics closer to the ThreadPool. Here is a code snippet that uses the new Task class:
Task t = Task.Create(DoSomeWorkMethod,
someInputValue);
A great illustration of the richness of the Task API can be seen in Figure 1.
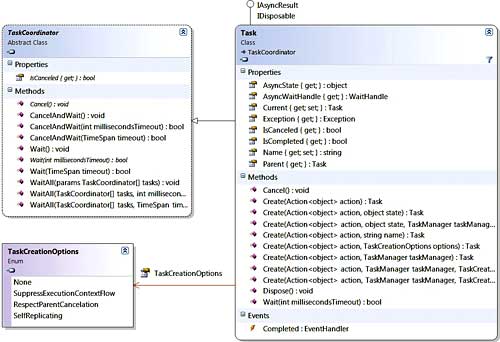
Figure 1
Notice how we can be notified (via the Completed event) when a Task completes, or we can poll about completion (via the IsCompleted property). Similarly we can check the IsCanceled property and also request to Cancel a task via the homonymous method. We can even request to CancelAndWait thus blocking on that call. Waiting is fully supported via many overloads of Wait and WaitAll and even by explicitly exposing a WatHandle which aids in integration with existing .NET APIs.
Think of Tasks as lightweight units of work that may run concurrently if “it is worth it”. In other words, the engine may decide to run a Task on the calling thread if it decides it is not worth executing it on a separate thread. Tasks are passed on (internally) to a TaskManager, which is at the heart of the Parallel Extensions library (with its internal and private friends). The diagram in Figure 2 depicts the TaskManager and the TaskManagerPolicy via which it can be configured.
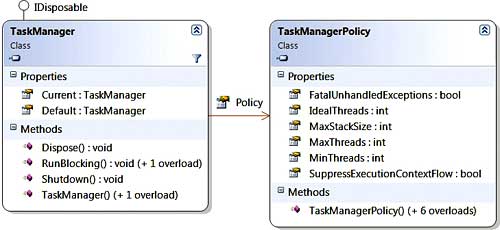
Figure 2
Think of TaskManager as a fancy threadpool. It represents a scheduler group that can be configured via policy and can be cleanly shutdown. An instance of TaskManager gets implicitly created per AppDomain, but you can also create one explicitly for isolation. The TaskManager creates (by default) one thread per core, and it then queues work items (i.e. Tasks) onto the respective queues of those threads. If a worker thread has finished processing its own work items, it can then “steal” work items from the other threads’ queues, thus keeping both cores busy all the time and offering us the best performance possible. In this way, we don’t get additional Threads which eventually would degrade overall performance. However, if one of the threads becomes blocked and does not fully utilise one of the cores, then additional threads get injected to process the work item queue and they are then later retired so as to bring down the number of worker threads to the ideal of one per core.
Consider the following code snippet. We use an anonymous method when creating the outer Task and we are also using a different overload of the Create method, one that does not accept the state to pass into the method but instead accepts a TaskManager:
TaskManagerPolicy tmp = new TaskManagerPolicy(1, 1, 1);
TaskManager tm = new TaskManager(tmp);
Task tPar = Task.Create(delegate
{
// do some work
Task tChi = Task.Create(DoSomeWorkMethod,
TaskCreationOptions.RespectParentCancelation);
// other work
}, tm);
Notice how we create a TaskManager configured the way we wish and associate it with Tasks that we create. In this example we only want to use a single thread to execute everything and thus verify the correctness of our code before worrying about potential synchronisation bugs. Also in the example above notice how there is an implicit child parent relationship between Tasks tPar and tChi. Also notice how we altered the creation options of the tChi so that is also gets cancelled should its parent Task gets cancelled (the default is the opposite).
If you are interested in other opportunities with regards to imperative task parallelism, as an exercise for home, I suggest that you explore the Future class which derives from Task and enables a programming technique known as dataflow programming. All the types mentioned in this section can be found in the System.Threading.Tasks namespace.
Imperative Data Parallelism, aka using the Parallel class
If we turn our attention to the System.Threading namespace of the December CTP, we find three types. The static Parallel class and its methods are a higher level API that encapsulates common patterns for achieving data parallelism. You can think of them as helpers for creating and working with Tasks, since that is what the implementation does internally (it creates SelfReplicating tasks). Let’s consider the following simple example:
foreach (string ip in arr)
{
Console.WriteLine(ip + TID);
Program.SimulateProcessing();
}
Where arr, TID and SimulateProcessing are defined as:
static string[] arr =
Directory.GetFiles(
@”C:\Users\Public\Pictures”, “*.jpg”);
static void SimulateProcessing()
{
Thread.SpinWait(500000000);
}
static string TID
{
get
{
return “ TID = “ +
Thread.CurrentThread.
ManagedThreadId.ToString();
}
}
Executing this code on a dual-core machine and pointing to a folder with 16 photos will take approximately 16 seconds, will utilise only one core and will of course use only 1 thread. Now, let’s change the calling code so instead of using an explicit loop, we change to using the Parallel class:
Parallel.ForEach<string>(arr,
delegate(string ip)
{
Console.WriteLine(ip + TID);
Program.SimulateProcessing();
}
);
Executing this code on a dual-core machine will take approximately 8 seconds, will utilise both cores and will of course use 2 threads. In other words, the Parallel class is utilising internally Tasks as described in the previous section. Notice how the translation from one snippet to the other is almost mechanistic once you know how to use the method.
There are many other overloads for ForEach (and indeed the For) methods on the Parallel class to support more advanced scenarios. The easiest way to glance at these signatures is in the Object Browser of Visual Studio (see Figure 3).

Figure 3 [Click to enlarge]
{kind=link}
Let’s explore a slightly more complex scenario. Consider the previous code but this time enhanced with the ability to be able to break out of the loop based on some condition (in our case the existence of the word “moth” in one of the file names):
foreach (string ip in arr)
{
Console.WriteLine(ip + TID);
Program.SimulateProcessing();
if (ip.Contains(“moth”))
{
break;
}
}
How can we translate this for the parallel version? Using a break statement of course will not compile, and even if it did, you have to remember that the code block is being potentially executed by many threads concurrently, which means that we need a mechanism, to stop all of them, not just the one that encounters the satisfying condition. The following snippet demonstrates an overload where the delegate gets passed in an extra member that aids with our goal:
Parallel.ForEach<string>(arr,
delegate(string ip, ParallelState ps)
{
Console.WriteLine(ip + TID);
Program.SimulateProcessing();
if (ip.Contains(“moth”))
{
ps.Stop(); // notifies all threads
return;
}
}
);
The snippet is so simple as to be self-explanatory.
Now let’s make our original example even more complex by introducing the idea of aggregating some value across iterations:
long sum = 0;
foreach (string ip in arr)
{
sum += ip.Length;
Console.WriteLine(ip + TID);
Program.SimulateProcessing();
}
Console.WriteLine(sum.ToString());
How can we parallelise the code above? A naive approach would be to directly access the sum variable in the delegate we pass in to the Paralle.ForEach method. This would be error-prone because there is a synchronisation issue of course with accessing the same variable from multiple threads in an unprotected manner. So, we could introduce a lock (or use the Interlocked class), but then we would be negating some of the performance benefits of parallelisation. Instead, there is another overload we can use that offers a solution for sharing state cross-iterations:
long sum = 0;
Parallel.ForEach<string, long>(arr,
delegate() { return 0; },
delegate(string ip, int index_in_arr,
ParallelState<long> ps)
{
ps.ThreadLocalState += ip.Length;
Console.WriteLine(ip + TID);
Program.SimulateProcessing();
}
,delegate(long tls) {
Interlocked.Add(ref sum, tls);
}
);
Console.WriteLine(sum.ToString());
Notice how this time we are using the generic version of ParallelState that we used earlier on. Also notice how we pass into the method two additional delegates: One for initialising the state and one for safely aggregating (once per thread) the interim sums.
I hope at this stage you can see the benefits of this higher level API, instead of having to work directly with Tasks. I’d encourage you to explore the For method and some of the overloads that I haven’t used here, in particular the ones that accept a TaskManager and TaskCreationOptions as arguments. You can also have a play with the Parallel.Do method that has nothing to do with loops and instead is a convenient way of invoking multiple delegates in parallel.
Declarative Data Parallelism
Declarative Data Parallelism is also known as Parallel LINQ (PLINQ) it is the final namespace that we are going to explore in the Parallel Extensions library. System.Linq contains the implementation of Parallel LINQ (PLINQ). It Enables LINQ developers to obtain multiple cores from their LINQ expressions by running any LINQ-to-objects query using data parallelism. PLINQ fully supports all .NET query operators and has minimal impact to the existing LINQ model.
First let’s show some basic LINQ code and remind ourselves of the way LINQ to Objects works. Assuming we have a method defined as:
private static bool IsDivisibleBy5(int p)
{
// Simulate long processing so we can show off PLINQ later
for (int i = 0; i < 10000000;
i++){i++; i--;}
return p % 5 == 0;
}
…the following LINQ snippet would output the total count of the numbers between 1 and 1000 that are divisible by 5 (i.e. “200”):
IEnumerable<int> arr = Enumerable.Range(1, 1000);
var q =
from n in arr
where IsDivisibleBy5(n)
select n;
List<int> list = q.ToList();
Console.WriteLine(list.Count.ToString());
The SQL-like syntax of the LINQ query statement is conceptually the equivalent of this single statement with no usage of lambda expressions, extension methods or type inference, also split over multiple lines for clarity:
IEnumerable<int> q =
Enumerable.Select<int, int>(
Enumerable.Where<int>(
arr, delegate(int n) { return
IsDivisibleBy5(n); }
),
delegate(int n) { return n; }
);
In other words, a LINQ-to-objects query is typically a chained series of method calls to extension methods that reside in System.Linq.Enumerable (in System.Core.dll of .NET Framework v3.5) that act on IEnumerable<T> by accepting delegates. The result of the calls ends up in the variable q, which in the example above would really be an IEnumerable<int>.
If you are not familiar with LINQ at all, please read my explanation of the new C# 3.0 and VB9 language features and how LINQ to objects works on my blog.
Now, glance back to the concise version of the LINQ query and let’s examine the code required to parallelise that query:
IEnumerable<int> arr =
Enumerable.Range(1, 1000);
var q =
from n in arr.AsParallel()
where IsDivisibleBy5(n)
select n;
List<int> list = q.ToList();
Console.WriteLine(list.Count.ToString());
Can you spot the difference? We can potentially make LINQ-to-objects queries run faster and scale better on multi-core machines simply by using the Parallel Extensions library and applying the AsParallel extension method to the source! If we take our PLINQ statement above and expand it to the long form like we did with the LINQ query earlier, this is the conceptually equivalent:
IParallelEnumerable<int> q =
ParallelEnumerable.Select<int, int>(
ParallelEnumerable.Where<int>(
ParallelQuery.AsParallel<int>(arr),
delegate(int n) { return
IsDivisibleBy5(n); }
),
delegate(int n) { return n; }
);
So, by injecting the AsParallel method we turned the source from an IEnumerable to an IParallelEnumerable and thus we also injected our own extension methods that reside in System.Linq.ParallelEnumerable (in System.Threading.dll). The class diagram in Figure 4 shows the five types involved in PLINQ.
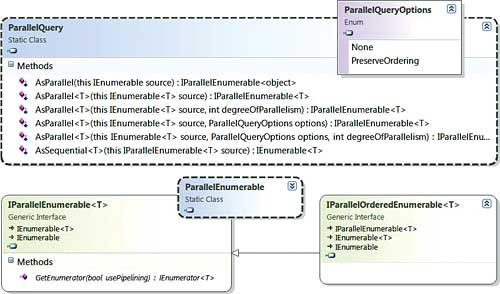
Figure 4
As you can see, IParallelEnumerable inherits from IEnumerable and hence can be used in all the places that IEnumerable can. The ParallelEnumerable static class has almost 200 extensions methods that are the parallel equivalents of the methods in Enumerable. It is in the implementation of these extension methods that the query gets parallelised. Also note on the class diagram the static ParallelQuery class that has a few overloads for the (seemingly) magic AsParallel extension method. The overloads allow you to configure the degreeOfParallelism; this is the equivalent of configuring the policy on the TaskManager for specifying the ideal number of threads you’d like to use (instead of the default of one worker thread per core).
AsParallel also allows you to pass in the ParallelQueryOptions so you can specify preserving the input-to-output ordering, which would ultimately bring the IParallerOrderedEnumerable in play. This latter point may not be immediately obvious, but it makes sense when you think about it. By parallelising your query, the source is being processed by multiple threads so the results will not be in any specific order unless the implementation specifically tried to achieve that. Preserving the order is of course an extra step and hence you are giving up some of the performance gains by requesting for order preservation, so only do so for cases where it is explicitly required.
There are some optional considerations for advanced users such as changing the mode of consumption: pipelining vs stop-and-go vs inverted. I won’t go in depth in this article on these options, but just so you know where to explore, consider the following teasers. In the example above where we used the ToList extension method, we are using stop-and-go processing where the results are aggregated in the end. That is likely more optimal than using pipelining where the results are combined as they become available. Pipelining gets used by default when you iterate through the results of a query, e.g. in a foreach loop. To turn off pipelining when iterating, you have to explicitly use the overloaded GetEnumerator method that accepts a Boolean on the IParallelEnumerable interface (see the class diagram above again). Finally, the most efficient mode is inverted which you can achieve by explicitly using the PLINQ-specific extension method ForAll. I leave it as an exercise to you to explore with code the performance characteristics of each consumption mode.
In closing, you would expect PLINQ to be using internally Tasks, and indeed that is the current plan for the final version, but it is not in this first CTP. This doesn’t affect your ability to evaluate the public API or observing the performance benefits, but I thought it was worth mentioning in case you “lifted the bonnet” with your favourite disassembler and could not see the relationship.
Hungry for more?
In each the sections above we explored how to use the API in this first Community Technology Preview of the Parallel Extensions to the .NET Framework. In each of the three parts, I finished off by leaving something further for you to explore in your own time after giving you a teaser where to start. The final area that I will leave unexplored in this short article is exception handling. There is a common exception handling strategy for the entire library. Since our code is parallelised, exceptions (even of different types) can be thrown on multiple threads. Since we are not explicitly using the threads though, the library will throw just a single exception for us: AggregateException. By looking into the InnerExceptions collection of this exception, we can find the individual exceptions that got thrown and their call stacks. I leave it to you to explore that in your code samples.
In a future drop of this library, there are plans for a fourth area to learn and experiment with: Coordination Data Structures (CDS). Until then, I hope this CTP gives you a lot to think about and I hope that you are downloading the assembly right now.
Remember that everything in the library is subject to change. The reason the team released this early CTP is to solicit feedback on the public API surface, and I know that they are already acting on comments received. In addition to the public interfaces, the one area that I would expect to improve multi-fold the closer we get to a production release, is performance.
There is a dedicated area on the connect site for submitting bugs, a dedicated forum for asking for help, a dedicated MSDN dev centre and of course the team’s blog. You can find the URL links to all of these plus to the download location of the library itself from my blog.
Daniel Moth is a developer, speaker and author who works for Microsoft UK in the Developer and Platform Group.
Comments