In a previous article I looked at how to create an initial Rails application, how to set-up the database used by the application and how to run some simple code from the Ruby console. In this article I’ll look more at the MVC nature of Rails and in particular how Rails routing works. In the future I will talk about testing a Rails application.
Browsing to the Application
In the first article I run several scripts to create models and to create the database tables associated with those models. The scripts also create simple controllers and views to display the data. I created User, Blog and BlogEntry models along with the associated tables and showed the SQL that was created. This code is part of a functional application that can be used straight away. If I point my browser are http://localhost:3000 I get the ‘home’ page shown in the first article. However, if I point it at http://localhost:3000/blogs I get something similar to that shown in Figure 1.
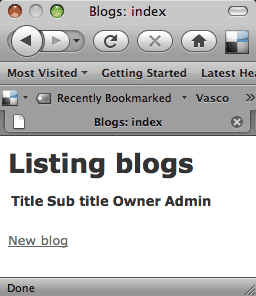
Figure 1: The home page
The controller is trying to display a listing of all the blogs in the database (currently there are none) and the page shows a link to allow the creation of a new blog. The URL of that link is
http://localhost:3000/blogs/new…and clicking on it takes me off to another page that looks like that shown in Figure 2.
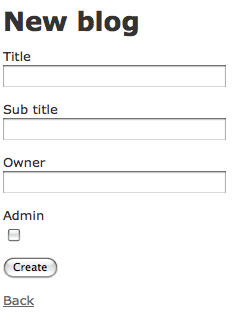
Figure 2: The Blog page
Remember that at this point I’ve done no coding other than run the generate scripts. For free, Rails gives me the routing and the UI. Now obviously, I hope, this is very much the start of the process. It’s nice to be up and running quickly and it’s nice to be able to try things out, but don’t be fooled into thinking that life is easy because of this. It’s certainly easier but there’s still lots to be done to get a fully working application.
Application Structure
A Rails application has a standard directory structure that I showed in the previous article. The generated code for the application’s models, views and controllers lives in the app directory. Looking in that directory there are sub directories for each of these and also a subdirectory called helpers. Taking these one at a time, the models directory contains one Ruby file per generated model. Those models are mostly empty, so for example, blog.rb looks like this:class Blog <
ActiveRecord::Base
end
Most of the information about the model is held in the migration, which essentially means the database.
The controllers on the other hand contain much more code. There is one Ruby file per controller and each of these files contains one method per action that can execute on that model, I will look at this more closely in a moment. Finally the views directory contains files that end with .html.erb. The names of these files follow the names of methods in the controller. For example, there is a blogs_controller with an index method and there is a blogs/index.html.erb file. Erb stands for Embedded Ruby and erb files are templates containing HTML and executable Ruby code, similar to other templating languages such as ASP.Net, PHP or JSP.
Rails works on the basis of convention over configuration. What this means here is that the controllers and the views are tied together by name. There is no external XML (or YAML) to tell the controller which .erb file to render for a particular request, instead the controller “knows” because of the conventions in place. So that when the user enters the URL shown above (http://localhost:3000/blogs) then Rails will execute the index action within the blog controller and this (by default) causes the blogs/index.html.erb page to be rendered.
Routing
Convention also plays its part when routing a request to a controller. Rails examines the URL of the request, the HTTP verb (GET or POST for example) and based on this decides which controller to use and which action to execute. Given the URL http://localhost:3000/blogs and assuming this is an HTTP GET, Rails will see the ‘blogs’ part of the URL and look for a controller called blogs_controller. As there is nothing further to the URL and this is a GET, Rails looks for a method called index within that controller. By default, after the index method is executed Rails will look for a page in views/blogs called index.html.erb to render. If the URL looked like http://localhost:3000/blog_entries/new (again assuming GET) then Rails looks for the blog_entries_controller class and a method called new and then renders the page in views/blog_entries called new.html.erb. All very straightforward, but there’s a lot of work under the covers to allow this to happen.
I’ve already shown that Rails generates code for us and for the most part Rails developers work either with the generated code or in the same areas. By this I mean that most of the development time is spent in the model, view, controller or migration directories.
However the heart of a Rails application is in none of these places. I would argue that the heart of a Rails application is the routing. Understand the way that Rails routes request and you are a large part of the way to being a competent Rails developer. I say this partly because so many of the helper functions that Rails provides depend on the routing architecture. For example in the views/blogs/index.html.erb file mentioned above is a line that looks like:
<%= link_to 'New blog', new_blog_path %>…that renders to:
<a href="/blogs/new">New blog</a>The helper function (link_to) has to know how to generate the /blogs/new URL and this is where routing comes in.
Routing information is held in the config/routes.rb file. The file (without the comments) looks like:
ActionController::Routing::Routes.draw
do |map|
map.resources :blog_entries
map.resources :blogs
map.resources :users
map.connect ':controller/:action/:id'
map.connect
':controller/:action/:id.:format'
end
This is Ruby code that ‘draws’ the routes.
Starting at the bottom, the call to:
map.connect ':controller/:action/:id'
…creates the default route. This says ‘map a URL of /foo/bar/n’ to a controller called ‘foo’ with an action of ‘bar’ and a parameter of ‘n’ (the .:format allows rails to serve up different data formats such as .xml). The other three entries are more interesting. When I ran the generate script to create the blog scaffold I ran this command:
script/generate scaffold blog
title:string sub_title:string
owner_id:integer admin:boolean
As well as generating code this script adds an entry to the routes.rb file, (notice that the entry is for blogs not blog). This single entry:
map.resources :blogs
…generates all the routes for the blogs controller.
To see what these routes are we can run a rake command. From the command line if I run:
rake routes
I see (something like) this (note that I’ve left out the .:format routes, but they are generated as well):
blogs GET /blogs {:action=>”index”, :controller=>”blogs”}
POST /blogs {:action=>”create”, :controller=>”blogs”}
new_blog GET /blogs/new {:action=>”new”, :controller=>”blogs”}
edit_blog GET /blogs/:id/edit {:action=>”edit”,¤:controller=>”blogs”}
blog GET /blogs/:id {:action=>”show”, :controller=>”blogs”}
PUT /blogs/:id {:action=>”update”, :controller=>”blogs”}
DELETE /blogs/:id {:action=>”destroy”, :controller=>”blogs”}
This tells us that there are seven routes generated (fourteen if we count the .:format routes) that map through four unique URLs combined with four HTTP verbs to seven actions. For example a GET request to /blogs/1 will execute the ‘blogs’ controller’s ‘show’ method passing the parameter 1, while a DELETE request to the same URL will execute the ‘destroy’ method. These routes allow me to access blogs (a collection of Blog) and an individual Blog within the blogs collection.
The values in the first column (blog, new_blog etc.) are the names of the routes. Only some of the routes are named, notably the routes available via GET. And these are the names that can be used in code. As we saw above, in the views/blogs/index.html.erb file metioned above is a line that looks like:
<%= link_to 'New blog', new_blog_path %>…that renders to:
<a href="/blogs/new">New blog</a>
The URL is retrieved by the call to the new_blog_path method. This method is available because of the new_blog route named in routes.rb. Similarly there will be a blogs_path, a blog_path and an edit_blog_path method amongst others.
Testing routes can be done in the Ruby console. I can run:
script/console…then use the same:
ActionController::Routing::Routes…type that the routes configuration file uses. In the console I can do this
rs = ActionController::Routing::Routes
This spews out a lot of information about the RouteSet and related types (several hundred lines worth on my terminal) that we can safely ignore. From here I can display the routes:
puts rs.routes
…which displays:
GET /blogs/
{:action=>"index",
:controller=>"blogs"}
POST /blogs/
{:action=>"create",
:controller=>"blogs"}
etc...
This is very similar to the rake routes output.
More importantly from the console I can test the routes, so to test what routing would do with a particular URL I can do:
>> rs.recognize_path "/blogs"
=> {:action=>"index",
:controller=>"blogs"}
I can also do the opposite, provide parameters and see what URL I would get:
>> rs.generate :controller => 'blogs',
:action => 'new'
=> "/blogs/new"
You can also use the console to experiment with routing, for example you could create a files to test routes (testroutest.rb, say) and load it like this:
>> load "config/testroutes.rb" => true
These test routes don’t interfere with your application (they are not in the routes.rb file) but can still be tested in the console.
Routing is very flexible, if I don’t want to use the standard behaviour I can define my own routes in the route.rb file and use that instead. For example, suppose I wanted to allow users to access a given blog entry by date, something like:
http://localhost:3000/blog/2008/12/24
I would need to define a route for this.
In the routes.rb file I could add an entry something like:
map.connect "blog/:year/:month/:day" ,
:controller => "blog" ,
:action => "show_date"
Here I specify that the controller is ‘blog’ and that the rest of the URL maps onto :year, :month and :day parameters of the show_date function. I can also set various requirements of the parameters such as they are allowed to be missing and that if they are present they must follow a particular regular expression, for example day must be a one or two digit integer.
I could also replace the default routing provided with map.resources with my own. For example suppose that I didn’t like the controller name ‘blog_entries’ (which is one of the controllers I generated for this article) and I wanted to use the name ‘blog’ instead. Also suppose I wanted to support multiple blogs each with its own ‘nickname’ such as kevinj or simonh, this would lead to URLs something like:
http://localhost:3000/blog/kevinj/1
…or:
http://localhost:3000/blog/simonh/1/edit
…to do this I would need to edit the routes.rb file taking out the default mapping for routes.rb and adding entries such as:
map.blog_entry 'blog/:nickname/:id',
:controller => "blog_entries",
:action => "show",
:conditions => {:method => :get}
map.edit_blog_entry
'blog/:nickname/:id/edit',
:controller => "blog_entries",
:action => "edit",
:conditions => {:method => :get}
Here the function following the map is the name of the route (blog_entries and edit_blog_entry). To have unnamed roots call map.connect:
map.connect 'blog/:nickname',
:controller => "blog_entries",
:action => "create",
:conditions => {:method => :post}
Now I can use these routes in the same way as before, so in a .html.erb file I can do something like:
<%= link_to 'Back',
blog_entry_path(:nickname =>
@blog.nickname) %>
…where blog_entry_path comes from the named route and :nickname is retrieved from a blog model’s nickname field. This will generate the following URL:
http://localhost/blog/kevinj/1
This shows that the routing framework is very flexible and it’s built into the fabric of Rails.
From controllers to views
When users make a request to the above URL several things have to happen. The request is routed by Rails to the appropriate controller. The method on the controller that corresponds to the action is then called. This method will go to work on the appropriate model (or models). When control returns from the controller then the appropriate view has to be rendered, which, this being Rails, is again a matter for convention over configuration.
Taking an example from above, a request to http://localhost:3000/blogs will send a GET request to the blogs_controller’s index method.
def index
@blogs = Blog.find(:all)
respond_to do |format|
format.html # index.html.erb
format.xml { render :xml => @blogs }
end
end
This method first gets a collection of Blog instances by using the find class method of Blog. Rails finder methods are very flexible, in this case I am calling the basic find passing :all to get all the Blogs back, but I could limit the search if I needed to. Rails also takes advantage of Ruby’s excellent support for meta programming by fabricating methods on the model classes based on the model’s relationships to each other, so for example you can call Blog.find_by_nickname(“foo”). This blog collection is stored in a variable called @blog. Any variable whose name starts with an @ symbol is an instance variable in Ruby, so this instance data is added to the current object. In a moment I’ll show you where this gets used. The following lines select the view to render. In reverse order, if the extension is XML the call the render method passing setting the :xml value to @blogs. If the format is HTML then do nothing! Do nothing in this case means do the default.
The default behaviour when leaving a model is to execute the view associated with this URL. Views are kept in the app/views directory and looking in there we’ll see a subdirectory called blogs. Blogs contains one .html.erb file for each GET, so index, new, show and edit. In this case the index view will be rendered as the index method was called on the controller. The index view looks like this:
<h1>Listing blogs</h1>
<table>
<tr>
<th>Title</th>
<th>Sub title</th>
<th>Owner</th>
<th>Admin</th>
</tr>
<% for blog in @blogs %>
<tr>
<td><%=h blog.title %></td>
<td><%=h blog.sub_title %></td>
<td><%=h blog.owner_id %></td>
<td><%=h blog.admin %></td>
<td><%= link_to 'Show', blog %></td>
<td>
<%= link_to 'Edit',
edit_blog_path(blog) %>
</td>
<td>
<%= link_to 'Destroy', blog, :confirm =>
'Are you sure?', :method => :delete %>
</td>
</tr>
<% end %>
</table>
<br />
<%= link_to 'New blog', new_blog_path %>
This is a .erb file, and the embedded Ruby is in the <% %> and <%= %> statements. If you use other template style web languages you will be familiar with this. Notice the link_to statement at the end of the file, this adds a URL to the page that the user can click on. However there are a couple of odd things on the page. Firstly the page is not complete, there’s no <html> tag for example, I’ll show where that comes from in a moment. Secondly, notice the use of the @blogs variable. The view and the model are separate classes, yet it seems that the view has access to the model’s data. What actually happens is that Rails smuggles the model’s instance data across to the view and makes it available as instance data on the view (remember that this is a Ruby class).
I said that the above page is incomplete, there is no <html> element for example, so where does the rest of the HTML come from? On most web sites pages share the same layout and it’s only the page content that is different. Duplicating this layout across multiple pages is a bad idea so most web development languages offer a way to provide a template of the whole page, and let individual pages plug in their data. Rails does the same thing. Rails templates are called layouts and are stored in the views/ layouts directory. By default there is one layout per controller, so in this application there are blog_entries, blogs and users layouts. The default behaviour (convention again) of a Rails application is to use the layout associated with the controller. The blogs layout is a .html.erb file:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML
1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/
DTD/xhtml1-transitional.dtd">
<html xmlns=http://www.w3.org/1999/xhtml
xml:lang="en" lang="en">
<head>
<meta http-equiv="content-type"
content="text/html;charset=UTF-8" />
<title>Blogs:
<%= controller.action_name %>
</title>
<%= stylesheet_link_tag 'scaffold' %>
</head>
<body>
<p style="color: green">
<%= flash[:notice] %>
</p>
<%= yield %>
</body>
</html>
The yield call gets the text of the rendered page and displays it.
You can override the default layout mechanism in a couple of ways. The base class for all controllers is Application Controller (in app/controllers/application) and in here you can add a call to the layout method:
layout "general"
…for example. All controllers will now use this layout. You could of course put that same call into individual controllers so that all methods on the controller use that layout.
Finally in an individual controller action rather than using the default rendering you could call the render method and turn off layouts:
render :layout => false…or specify a different layout:
render :layout => "blue"
Conclusion
In these two articles I’ve taken a short tour around Rails. What I’ve tried to do, rather than simply concentrate on the basics such as the MVC model is to talk about some of the other features such as migrations, the REPL (Read Execute Print Loop – or the Ruby console I showed in the first article) and the routing. These features are extremely important and form the core of developing in and understanding Rails. Hopefully this has piqued your interest in this environment.
Comments