There exists plenty of real world data that simply do not fit into structured organization. Documents, web pages and email are some common examples. To store these data efficiently, in ways that allow them to be searched easily and rapidly, you will either have to “force fit” the data into a relational structure, or you need to turn to alternatives. The Lucene search engine, an open source 100% Java project from the Apache Software Foundation, is such an alternative.
This article introduces you to the basic concepts behind the Lucene search engine. You will see how to use Lucene’s Java API for indexing and search of textual data.
A hands-on example will fully index Shakespeare’s sonnet collection, allowing you to instantly search for any words or phrases across all of them. You will be able to extend the example code and even use it in your own text storage/management projects.
About Lucene
The Lucene project is one of the top-level projects at the Apache Software Foundation (ASF). All new projects at the ASF must first undergo incubation, until sufficient community adoption, stability and maturity has been reached, before becoming top level (and some projects never make it). This means that Lucene is ready for the real world, and you can put it into production use right away with a high level of confidence.Physically, Lucene exists as a set of Java APIs. You can use this set of Java APIs to index and search a large body of textual data, including the creation of full-text indexes. Full-text indexing enables you to search via any words, phrases, or sentence fragments across the entire body of text. Before you can use Lucene effectively, you need to understand some basic Lucene concepts and terminology.
Basic Lucene concepts
The Lucene library creates and maintains indexes. In Lucene, an index is conceptually a sequence of Documents. A Document is a Lucene-specific Java class that consists of a set of Fields. Figure 1 illustrates this.
Figure 1: A Lucene document
In Figure 1, you can see that an index consists of a sequence of documents, and each document contains a set of fields. Using Lucene, you can index a body of text by creating a Document, and feeding all the Document instances to Lucene’s IndexWriter. The IndexWriter class creates and maintains the index. For example, if you are indexing all of Shakespeare’s sonnets, you can create a subclass of Document called SonnetDocument, and then creating an instance of SonnetDocument for each sonnet and feed it to Lucene’s IndexWriter.
Each field in Lucene is a name-value pair. The value is textual, can be a very long string, and can be tokenized for the index. For example, one field in a SonnetDocument may be named “path”, with the value storing the path and filename to the file that contains the text of the sonnet. Another field in SonnetDocument may be named “content”, and can contain the entire text of the sonnet. When feeding a large volume of text for the value of a field using an IndexWriter, you can pass an instance of java.io.Reader (sourced from, say, a file or a network URL).
Some values may be treated as atomic entities, and will not be tokenized for the index. For example, you may not want tokenized indexing if you are indexing on date values or email.
A field can be stored, in which case the entire text is stored within the index, and can be retrieved when hits are found during searching; or it can be stored elsewhere, in which case you are responsible for storing and retrieving the actual field value. For example, if you already have the text of the sonnets in separate files, you will not need the Lucene index to store the text again.
A Lucene index
While an index conceptually comprises Documents and Fields, Lucene maintains the index physically as a set of files in a directory. During indexing, Documents that are fed to the IndexWriter are merged into segments; it is the segments that are written to files in the index directory. Each segment is an independent index by itself. Figure 2 shows a Lucene index.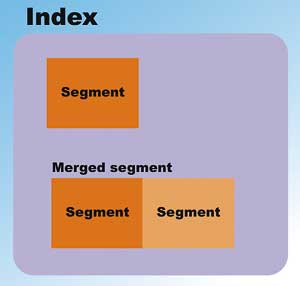
Figure 2: The Lucene index
In Figure 2, you can see that Lucene maintains an index in the form of segments (sub-index). Multiple segments can be merged together during maintenance or index optimization.
You can tune the performance of Lucene by adjusting several system properties. Consult the Lucene documentation on the use of these system properties; performance tuning is out of the scope of this introductory article.
Next, you will put Lucene to the test by indexing Shakespeare’s sonnets.
Working with Shakespeare’s sonnets
This example is a program that can perform the following:- Download the text of the Shakespeare’s sonnets over the Internet from Project Gutenberg, and store them into files
- Create a Lucene index of all the sonnets
- Allow the user to query for words or phrases in the sonnets
- Display the text of any sonnets
Class functions |
|
| Class Name | Description |
| WorksSlicer | This class will download the text of the sonnets over the Internet, and create a file for each one. The main() method for the application is also in this class. |
| SonnetDocument | Creates a Lucene Document for a sonnet. It has the file name of the sonnet as a field. The other field, called content, contains the entire text of the sonnet. |
| Indexer | This class has code that will create the index for the sonnets. It uses the StandardAnalyzer, and writes the index into a directory called “index”. |
| SonnetFinder | The code of this class will search the index for a sonnet, given a Lucene query. It uses Lucene’s QueryParser plus StandardAnalyzer to parse the query, and IndexSearcher to search the index. |
| SonnetViewer | Given a sonnet number, this class will display the full text of the sonnet. It does this simply by copying the content of the sonnet file to the console. |
The first class, called WorksSlicer, will download the sonnet text and creates a file for each sonnet. The code for WorksSlicer.java is shown below, with annotations:
package uk.co.vsj.lucene; import java.net.*; import java.io.*;worksURL contains the URL to the Complete Works of William Shakespeare, from Project Gutenberg, in text format. The sliceWorks() and readSonnets() methods take advantage of the specific format of the content. Each sonnet is preceded by a single line with the sonnet’s number, sliceWorks() uses String’s trim() method to eliminate leading blanks, and then Integer’s parseInt() method to detect these lines.
The sonnets data from Project Gutenberg is terminated with a line with the words “THE END” on it. WorksSlicer will terminate the sonnet search loop once this line is located.
public class WorksSlicer {
private static final String worksURL =
“http://www.gutenberg.org/dirs/
etext94/shaks12.txt”;
private void sliceWorks() {
URL urlLink;
URLConnection uc;
BufferedReader in = null;
FileWriter fo = null;
String inputLine;
int sonNum = 0;
try {
urlLink = new URL(worksURL);
uc =
urlLink.openConnection();
in = new BufferedReader(
new InputStreamReader(
uc.getInputStream()));
inputLine = in.readLine();
boolean notNum = false;
while (inputLine.indexOf(
“THE END”) == -1) {
notNum = false;
try {
sonNum =
Integer.parseInt(
inputLine.trim());
} catch (
NumberFormatException ex) {
notNum = true;
}
if (!notNum) {
if ((sonNum > 0) &&
(sonNum < 155))
readSonnets(
in, sonNum);
}
System.out.println(“**” +
inputLine);
inputLine = in.readLine();
}
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
in.close();
} catch (Exception ex) {
}
}
}
Once a sonnet is located, the readSonnets() method reads and stores the sonnet’s text. readSonnets() writes the text into a file named Sonnet? where the ? is the sonnet number.
private void readSonnets(
BufferedReader inReader, int sonNum) {
FileWriter fo = null;
System.out.println(
“—— IN READ SONNET”);
try {
fo = new
FileWriter(
“Sonnet” +
sonNum);
String inputLine =
inReader.readLine();
while (
inputLine.length() > 0) {
fo.write(inputLine
+ “\n”);
inputLine =
inReader.readLine();
}
} catch
(IOException ex) {
ex.printStackTrace();
} finally {
try {
fo.close();
} catch
(IOException ex) {
}
}
System.out.print(
“...” + sonNum);
}
private void readPlays(
BufferedReader inReader) {
}
The main() method determines what the program will do when invoked from the command line. If you pass the argument “createindex”, the sonnets will be downloaded using sliceWorks(), and the index will be created via Indexer.createIndex().
If you pass the arguments “view nnn”, where nnn is a sonnet number, the text of the corresponding sonnet will be displayed.
If you invoke without arguments, the program will prompt you to enter a Lucene query. The query will be used to search the index.
public static void main(String[] args)
throws Exception {
BufferedReader in =
new BufferedReader(
new InputStreamReader(
System.in));
if (args.length == 0) {
System.out.println(
“Please enter your query:”);
String qry = in.readLine();
SonnetFinder.searchFor(qry);
} else {
if (args[0].equals(
“createindex”)) {
WorksSlicer ws =
new WorksSlicer();
ws.sliceWorks();
Indexer.createIndex();
}
if (args[0].equals(“view”)) {
if (args[1] != null)
SonnetViewer.view(args[1]);
} // of if
} // of else
} // of main
} // class
Adding fields to a Lucene document
The SonnetDocument class creates a Lucene Document, specific for indexing the sonnet. The annotated code for SonnetDocument.java is shown below.package uk.co.vsj.lucene; import java.io.File; import java.io.Reader; import java.io.FileInputStream; import java.io.BufferedReader; import java.io.InputStreamReader; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field;The method called createDocument() is a class factory for Lucene Documents. You can see how the two fields, path and content, are added to the Document using the Document.add() method. In particular, Field.Text() is used to create the content field, which takes a Reader as content; this Reader is sourced from the file containing the sonnet text.
The static Field.Text() method creates a field that is not stored, meaning that the content of the sonnet text is not stored within the index.
public class SonnetDocument {
public static Document
createDocument(File f) throws
java.io.FileNotFoundException {
Document doc = new Document();
doc.add(Field.Text(
“path”, f.getPath()));
FileInputStream is =
new FileInputStream(f);
Reader reader = new BufferedReader(
new InputStreamReader(is));
doc.add(Field.Text(
“contents”, reader));
return doc;
}
private SonnetDocument() {}
}
Creating the sonnet index
The Indexer class is responsible for creating the index. Since the collection of sonnet is a read-only body of text, the index only needs to be created once. Lucene is fully capable of managing the index of data that may be written to or deleted; consult the Lucene documentation if you need more detail.The source code of Indexer.java is annotated below:
package uk.co.vsj.lucene; import org.apache.lucene.analysis.standard. StandardAnalyzer; import org.apache.lucene.index.IndexWriter; import java.io.File; import java.io.IOException; import java.util.Date;The IndexWriter class creates the Lucene index in the “index” directory. To create an IndexWriter, you need to pass in an Analyzer. An Analyzer tokenizes the content and may also filter it. Lucene comes with a StandardAnalyzer; this implementation analyzes content in the English language and will filter insignificant words such as “a” and “the” during index creation. Lucene also comes with Analyzers specialized for the German and Russian language.
Note the action of indexing, from the Lucene developer’s point of view, distils down to:
- Create an instance of IndexWriter, parameterized with an appropriate Analyzer
- Repeatedly create Document instances and add it to the index using IndexWriter.addDocument()
- Call IndexWriter.optimize() to optimize the index
- Close the IndexWriter
public class Indexer {
public static void createIndex() {
Date start = new Date();
IndexWriter writer = null;
try {
writer = new
IndexWriter(“index”, new
StandardAnalyzer(),
true);
for( int i=1; i< 155; i++) {
writer.addDocument(
SonnetDocument.createDocument(
new File(“Sonnet” + i)));
}
writer.optimize();
Date end = new Date();
System.out.println(
“Indexing took “ +
(end.getTime() -
start.getTime()) +
“ milliseconds”);
} catch (IOException e) {
e.printStackTrace();
}
finally {
if (writer != null)
try {
writer.close();
} catch (Exception ex) {}
}
}
}
Searching the index
You can submit queries against the Lucene index either using the Lucene APIs (programmatically), or ask Lucene to parse query commands in a query language.This example explores latter approach – using the query language parser. The SonnetFinder class will ask the user for a query and then pass it to the parser. The source code for SonnetFinder.java follows:
package uk.co.vsj.lucene; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis. standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.queryParser. QueryParser; import org.apache.lucene.search.Hits; import org.apache.lucene.search. IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.Searcher;The QueryParser class is the helper parser that will take a string in the query language and create a Lucene Query object. To create the QueryParser instance also require an Analyzer as input, the same StandardAnalyzer (as Indexer) is used for the English content. To search the index, you need to instantiate IndexSearcher. The IndexSearcher.search() method is used to perform the actual search. This method returns Hits, which is a ranked list of Documents. The nth ranked document in this list is accessible via the Hits.doc(n) method. For each Document in Hits, the value for the associated path field is displayed to the user in a list. This will reveal all the sonnet numbers that match the query. You will see how to use the query language a little later when you test the code.
public class SonnetFinder {
public static void searchFor(
String queryText) {
try {
Searcher searcher = new
IndexSearcher(“index”);
Analyzer analyzer = new
StandardAnalyzer();
Query query =
QueryParser.parse(
queryText, “contents”,
analyzer);
System.out.println(
“Searching for: “ +
query.toString(
“contents”));
Hits hits =
searcher.search(query);
int hitsCount =
hits.length();
System.out.println(hitsCount
+ “ matching sonnets
found”);
for (int i = 0;
i < hitsCount; i++) {
Document doc =
hits.doc(i);
String path =
doc.get(“path”);
if (path != null) {
System.out.println(
i + “. “ + path);
}
} // of for
searcher.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Displaying the text of a sonnet
The final class, SonnetViewer, does not make use of any Lucene APIs. It simply displays the content of a sonnet file. The code for SonnetViewer.java is shown below:package uk.co.vsj.lucene;
import java.io.File;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class SonnetViewer {
public static void view(
String sonNum) {
File f = null;
FileInputStream is = null;
System.out.println(“Sonnet “
+ sonNum + “\n”);
try {
f = new File(“Sonnet”
+ sonNum);
is = new FileInputStream(f);
BufferedReader reader =
new BufferedReader(new
InputStreamReader(is));
String curLine = null;
while ((curLine =
reader.readLine()) != null)
System.out.println(
curLine);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
is.close();
} catch (Exception ex) {
}
}
}
}
Testing your on-line Shakespeare library
To try out the code, you will need to:- Make sure you have JDK 1.4.2 or later installed and working
- Download and install Lucene (see textbox Downloading and Installing Lucene for details)
- Download and unarchive the code distribution (or key in the source code)
- Make sure you’re online and have Internet access
- Have about 5 MB of disk space available for the sonnets and index
Now, run the setpath.bat batch file to set the CLASSPATH.
Run the compile.bat batch file to compile all the source code. The run.bat batch file is supplied to make invocation of the application simple.
To create the sonnet files and the index, you can use the command line:
run createindexThis only has to be performed once. After running this, you can check the local directory and notice all the sonnet files created. If you change directory to the index subdirectory, you can also see the Lucene index files.
Now, you’re ready to search the sonnets. You can just issue the command:
runYou will be prompted to enter your query. Try to look for a word:
Please enter your query: deedsThe system returns a list of sonnets that contains the word “deeds”. You should see 10 matching sonnets, similar to:
Searching for: deeds 10 matching sonnets found 0. Sonnet37 1. Sonnet90 2. Sonnet94 3. Sonnet111 4. Sonnet121 5. Sonnet34 6. Sonnet61 7. Sonnet69 8. Sonnet131 9. Sonnet150You can also search for a phrase by using quotation marks, as in:
Please enter your query: “thy deeds”This time, “thy deeds” only matches 3 sonnets:
Searching for: “thy deeds” 3 matching sonnets found 0. Sonnet69 1. Sonnet131 2. Sonnet150It is also possible to search using the AND operator. The following query makes sure the sonnet contains both the phrase “thy deeds” and “my mind”:
Please enter your query: “thy deeds” AND “my mind”You will match only one single sonnet using the above query:
Searching for: +”thy deeds” +”my mind” 1 matching sonnets found 0. Sonnet150Note how the QueryParser has changed the query “thy deeds” AND “my mind” to +”thy deeds” +”my mind” – a more precise but completely equivalent form for the IndexSearcher.
To see the text of any sonnet, just use the command:
run view 150The query language has many more capabilities. For more sophisticated queries, consult the Lucene documentation.
Conclusions
Lucene is a unique product satisfying a real-world need relating to document management – the ability to index and quickly search through a very large body of text. Its open source heritage allows it to be applied to and used in a wide variety of real-world scenarios. Lucene’s Java API is easy to learn, and the system operation is straightforward. If you have been looking for a text indexing solution for your document management projects, look no further – Lucene is the answer to your prayers.Even if your project is not directly related to document management, you may still find use for Lucene when working with unstructured textual data that do not fit well into a RDBMS.
Sing Li is a consultant, system architect, open source software contributor, and freelance writer specialising in Java technology and embedded and distributed systems design. He has authored or co-authored several books on the topic, including Professional Apache Tomcat (Wrox), Professional JSP 2 (Apress), Early Adopter JXTA (Wrox), and Professional Jini (Wrox).
About Project GutenbergProject Gutenberg is the first and largest producer and distributor of free electronic books (ebooks) over the Internet.The founder of Project Gutenberg, Michael Hart, is the inventor of the ebook concept (back in 1971). |
Downloading and installing LuceneYou can download the latest binaries for Lucene.After you have unarchived the binary distribution, you will have documentation, sample code, and library JAR files. Since Lucene is an API library, all you need to do is make sure that the library JAR is in your CLASSPATH when you are building and running your Lucene applications. The latest version available at the time of writing is 1.4.3, and the library JAR is called lucene-1.4.3.jar. |
Comments